
「MUM」運作時有三個流程:了解語言背後含意、透過多路分析判斷,深入了解資訊,最後做出比對結果,但是光是第一個步驟就會面臨極大挑戰,比方目前對應新型冠狀病毒的17款疫苗,至少就透過50種語言以超過800種名稱稱呼,其中輝瑞疫苗或莫德納疫苗均有不同稱呼方式,但是都是指相同疫苗,因此要在短時間理解判斷使用者所指內容細節,並且能讓使用者快速找到正確內容,勢必要改善現行Google Search背後使用語言模型。
讓Google Search搜尋結果更加精準
今年在Google I/O 2021期間,Google分別宣布兩種語言模型「LaMDA」 (Language Model for Dialogue Applications),以及「MUM」 (Multitask Unified Model),藉此詮釋未來在人機互動上的想像。而Google搜尋研究員暨副總裁Pandu Nayak在線上訪談中,更具體解釋「MUM」背後運作原理,以及未來預計應用發展方向。
讓系統以更全面形式判斷使用者提問內容
按照字面上解釋,「MUM」是由「Multitask Unified Models」三個字縮減為稱,主要會分析字句中的關鍵內容進行比對,而不是僅作全面比對,因此與現行應用在Google Search的BERT、GPT-3模型採不同運算模式。
以先前在Google I/O 2021舉例內容來看,當使用者說明先前已經完成在亞當斯山的徒步旅行,接下來希望嘗試挑戰富士山,若是以往的語言模型判斷結果,可能就會直接顯示富士山相關資訊,讓使用者自行檢視相關搜尋內容。
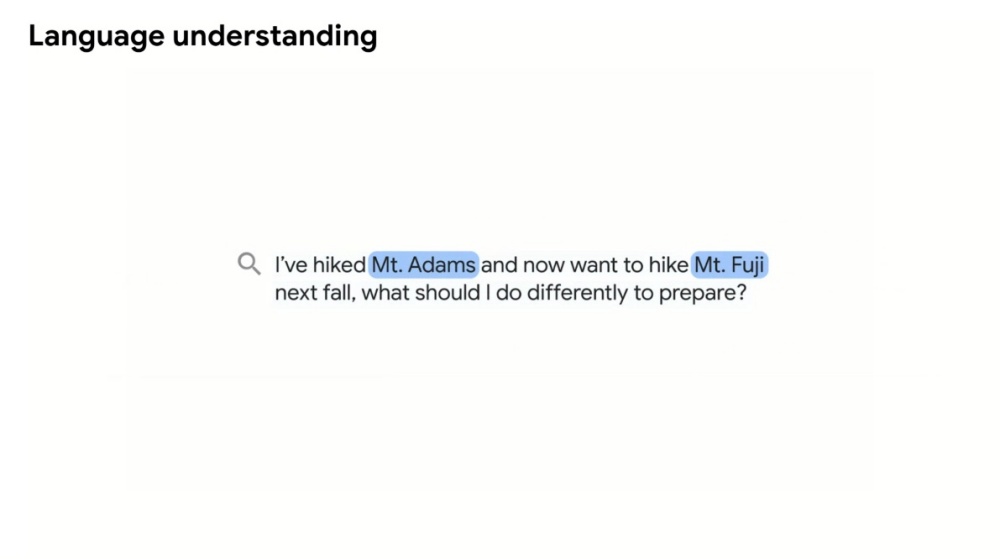 ▲「MUM」會針對語句中關鍵內容進行判斷,並且找出主要字句作為判斷依據,例如以亞當斯山與富士山作為主要比較條件
▲「MUM」會針對語句中關鍵內容進行判斷,並且找出主要字句作為判斷依據,例如以亞當斯山與富士山作為主要比較條件
但在「MUM」語言模型運作下,系統會從使用者的描述中抓出關鍵比較條件,例如使用者已經去過亞當斯山,並且是以徒步旅行方式完成,因此會以此條件作為基礎,進而與場景換成富士山,同在相同徒步旅行的條件下作比較,不會出現相同場景卻有比較條件基礎不一樣的情況。
另外,由於「MUM」會進一步讓系統了解人類語言結構與文字在不同情況下所代表意義,而非只是進行文字上的條件理解判斷,因此在互動過程中會記下先前提問內容,讓系統能在符合前因後果情況下正確回答問題。
因此當使用者在後續互動中提到計畫秋天時啟程,同時也透過拍攝登山靴照片詢問是否適合穿著使用時,系統就會透過畔對先前提及計畫前往富士山的條件,進而查詢富士山過去在秋天時的氣候狀況,並且透過影像識別判斷使用者所拍攝的登山靴,是否適合在富士山徒步旅行使用,避免出現錯誤判斷情況。
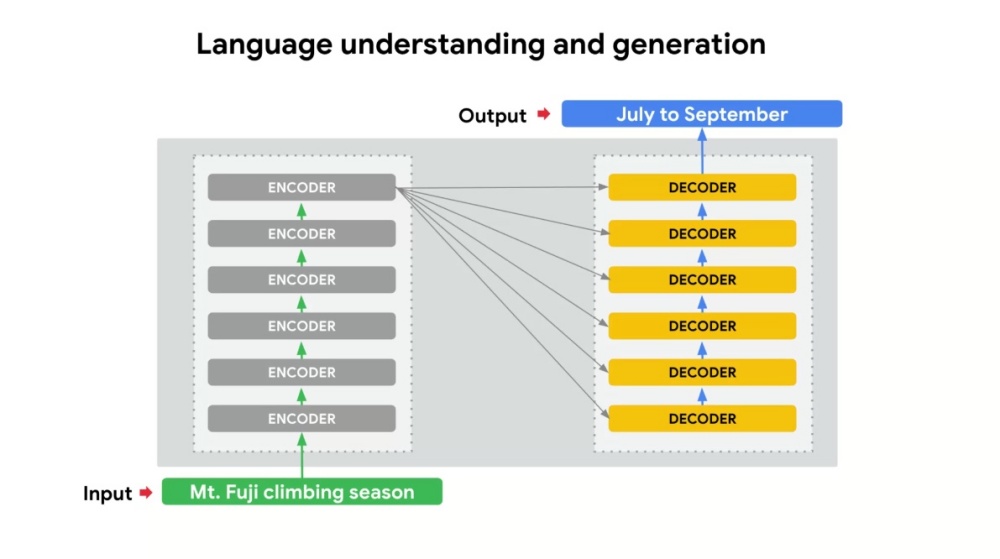 ▲透過多工方式了解語言背後含意,例如提問內容包含適合富士山爬山的季節時,系統會自動透過資料比對得知適合爬山時間為7-9月,並且以此作為搜尋比對條件之一
▲透過多工方式了解語言背後含意,例如提問內容包含適合富士山爬山的季節時,系統會自動透過資料比對得知適合爬山時間為7-9月,並且以此作為搜尋比對條件之一  ▲透過多路分析比對找到合適解答
▲透過多路分析比對找到合適解答  ▲比對不同資訊內容,藉此判斷使用者提問爬過亞當斯山的情況下,換成爬富士山是否會有困難
▲比對不同資訊內容,藉此判斷使用者提問爬過亞當斯山的情況下,換成爬富士山是否會有困難
讓機器了解人類語言是相當大的挑戰,將以「MUM」精進Google Search搜尋結果
目前Google已經累積訓練75種主要語言,藉此建立「MUM」語言模型,並且透過多路流程讓系統分析判斷使用者藉由文字、影像或語音等方式搜尋需求,進而找出最佳解答。在過程中,分別會透過第一個步驟了解語言背後含意,進而在第二步驟中透過東路流程進行判斷,最後一個步驟則是深入了解使用者希望查找內容,並且提供合適答案。
 ▲「MUM」運作時的三個流程:了解語言背後含意、透過多路分析判斷,深入了解資訊,最後做出比對結果
▲「MUM」運作時的三個流程:了解語言背後含意、透過多路分析判斷,深入了解資訊,最後做出比對結果
不過,光是第一個步驟就會面臨極大挑戰,比方目前對應新型冠狀病毒的17款疫苗,至少就透過50種語言以超過800種名稱稱呼,其中輝瑞疫苗或莫德納疫苗均有不同稱呼方式,但是都是指相同疫苗,因此要在短時間理解判斷使用者所指內容細節,並且能讓使用者快速找到正確內容,勢必要改善現行Google Search背後使用語言模型。
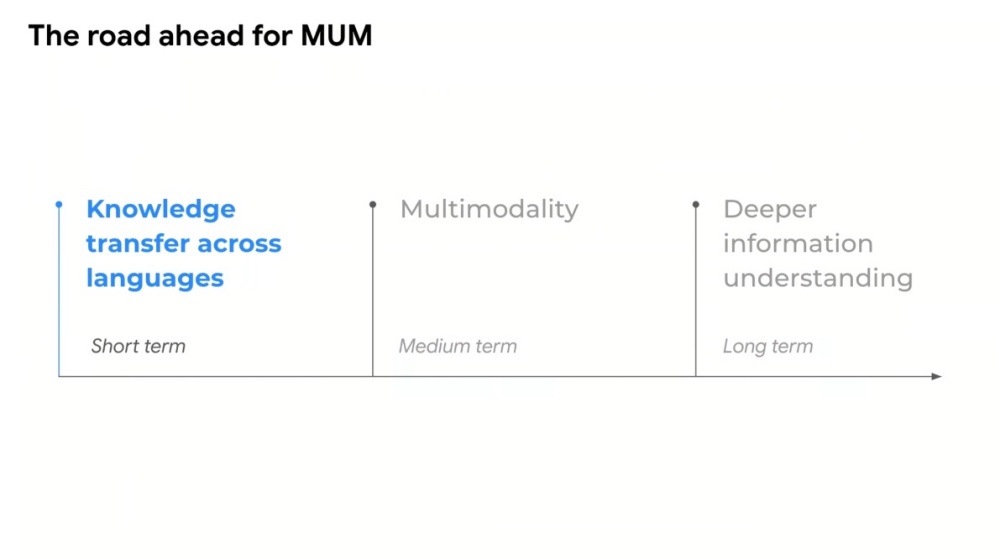
而透過「MUM」語言模型支援跨語言移轉知識能力,即可讓系統快速對應不同語言,並且尋找相同內容結果,就像使用者同時精通多國語言,可以透過不同語言詮釋相同內容,不會因為使用語言差異讓詮釋結果截然不同。同時,在系統學習全新語言之後,可直接與已經學習知識建立連結,無需重新學習,更凸顯「MUM」語言模型持續擴充彈性。
 ▲目前全球以50種語言稱呼的新型冠狀病毒疫苗名稱,目前已經超過800種
▲目前全球以50種語言稱呼的新型冠狀病毒疫苗名稱,目前已經超過800種
「MUM」不會取代現行使用語言模型,亦可學習無文字語言
Pandu Nayak強調「MUM」不會取代目前使用的BERT、GPT-3語言模型 (至少目前不會),而是會以強化形式讓Google Search更能理解使用者在搜尋過程所指內容。
而對於無法透過文字傳遞的語言,Pandu Nayak則說明目前建構語言模型所使用數據,其實不僅是文字內容,同時也包含影像、影片及聲音等內容,透過大量數據關聯之下,同樣也能讓「MUM」順利建構語言模型。
與「LaMDA」鎖定不同應用形式,但都會改變現有人機互動
至於跟先前同樣在Google I/O 2021期間提出,同樣也是讓系統了解人類語言的模型「LaMDA」,則是會更聚焦在對話式的互動,例如讓紙飛機或冥王星能以擬人形式與人「對話」。但相比「MUM」確定會應用在Google Search,「LaMDA」目前仍處於試驗階段,因此暫時未有明確應用規劃。
從Google今年提出兩種語言模型來看,其實可以更明確看見Google希望讓使用者更容易透過Google Search找到正確解答的發展方向,並且能創造全新人機互動體驗。
不過,目前包含「MUM」在內語言模型僅會用在Google Search,暫時沒有對外開放使用計畫。
 ▲強化「MUM」反應效率將是未來持續發展重點
▲強化「MUM」反應效率將是未來持續發展重點



















