
Google 推出多模態 Gemma 3n 模型,能在僅 2 GB 記憶體的裝置上處理圖片、音訊、影片與文字,適合行動端應用。
Google近期推出全新開源設計的裝置端多模態人工智慧模型Gemma 3n,標榜能將高效能模型佈署於裝置端,讓手機、平板與筆電等裝置也能具備過往僅限雲端模型的多模態運算能力。
目前Gemma 3n模型已經透過Hugging Face上架,同步提供完整技術文件與開發指南。
多模態架構設計,全面支援文本、影像、音訊與視訊
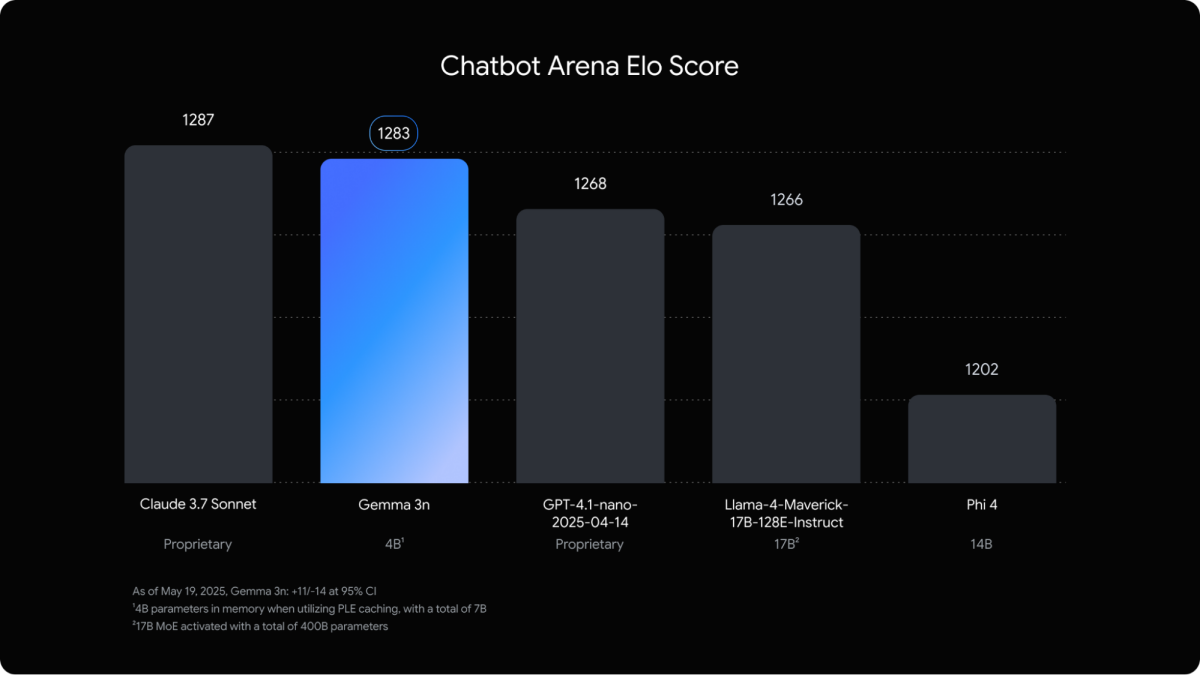
Gemma 3n最大亮點在於其原生支援影像、音訊、視訊與文字輸入,並且能輸出自然語言文字結果。此次發表版本提供E2B (有效參數約20億組)與E4B (約40億組)兩種版本,具備極高的運算效率,但實際效能卻可達傳統50億組與80億組參數規模的模型級別。
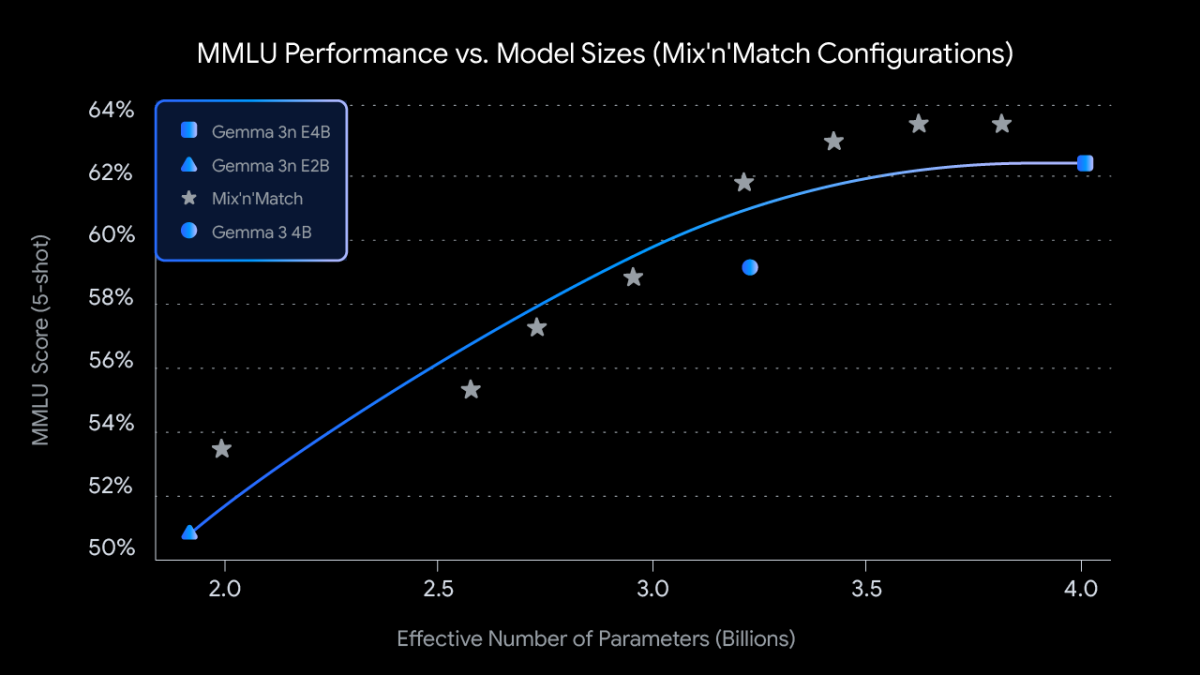
不僅如此,Gemma 3n採用全新MatFormer (Matryoshka Transformer)架構,主打彈性推理 (Elastic Inference),也允許開發者透過Mix-n-Match方法自由切換模型規模,可依照設備資源打造合適模型版本,裝置記憶體僅需2GB或與3GB容量即可順暢執行。
針對裝置端重新設計的記憶體架構:PLE每層嵌入技術
Gemma 3n採用名為PLE (Per-Layer Embedding)的技術,將部分參數配置至CPU、記憶體運行,僅將最關鍵的Transformer權重保留在人工智慧加速器,大幅提升記憶體使用效率,同時也讓較入門定位規格裝置可執行近似雲端等級模型推論能力。
支援更快長文本處理與語音翻譯:KV Cache與語音編碼器全面升級
面對長文本與多媒體序列輸入,Gemma 3n引入了全新KV Cache Sharing快取共享機制,加速首字生成的回應時間,針對視訊或語音串流處理更為即時。語音模組則導入源自Google USM的語音編碼器,支援語音辨識 (ASR)與語音翻譯 (AST),首波已經支援英語至西班牙語、法語、義大利語、葡萄牙語等多語對應。
全新MobileNet-V5:裝置端也能即時執行影像分析
視覺處理部分,Gemma 3n搭載了全新設計的MobileNet-V5視覺編碼器,支援256-768像素多解析度輸入,並且導入MobileNet-V4基礎與多尺度融合架構,實現在 Google Pixel Edge TPU發揮13倍加速、4倍記憶體用量減少,同時準確率也超越未進行蒸餾的SoViT方案。
Gemma 3n作為Google對「裝置端人工智慧」 (AI on Device)佈局的一次重大進展,不僅強化其在多模態模型的技術領先地位,也為未來人工智慧裝置運算鋪路。未來,Gemma系列也預計將持續以更小模型、更大效能為目標,在行動設備上實現更多原生人工智慧體驗。



















