Mozilla 在去年推出了獨特的開源專案"同聲計畫/ Common Voice ",藉由募集有志者朗誦網站內容貢獻自己的自然語言以及協助校正的方式,希望打造全球最大的開源語音資料庫,這項計畫同時也是語音辨識專案"深度語音辨識 Deep Speech "的基礎;而同聲計畫也在去年底將英文資料庫開放,同時在稍早正式宣布開始募集更多國家的語音內容,其中台灣的正體中文也成為首個納入同聲計畫的亞洲語言。



稍早 Mozilla 台灣也邀請三位與 Mozilla 開源創新、同聲計畫、深度學習技術的負責人,分別為開放創新團隊公關負責人 Alex Klepel ,創新部門數位策略師 Michael Henretty ,以及機器學習小組負責人 Kelly Davis ,針對同聲計畫的現況與展望進行訪談。
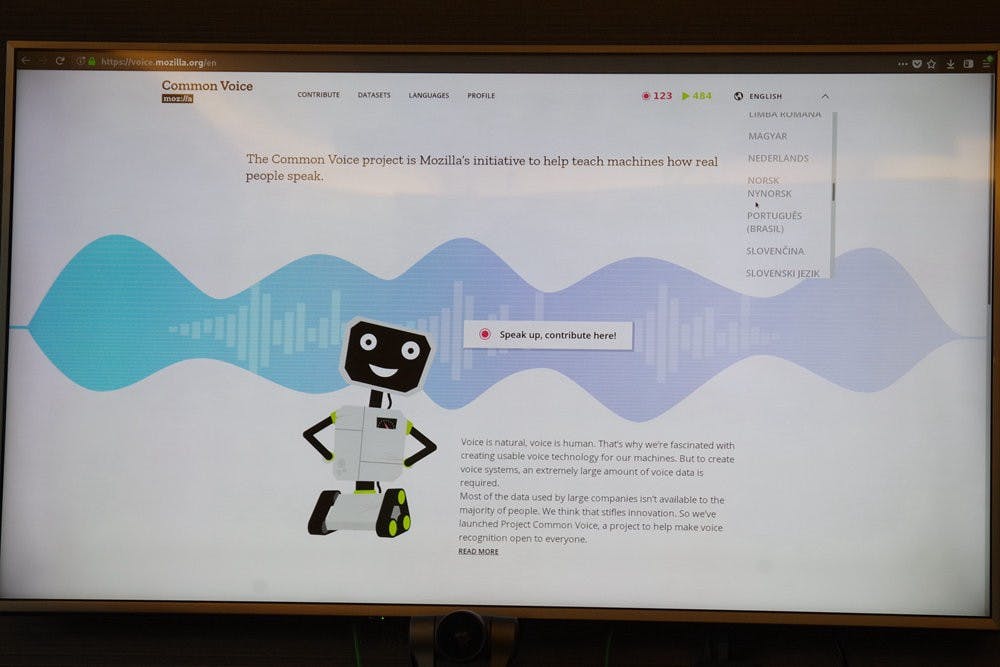

在開始介紹前,還是先簡單回顧一下同聲計畫在做甚麼吧;同聲計畫是 Mozilla 推動的一項開源語音資料蒐集計畫,利用網頁介面(註:由於 iOS 對於瀏覽器存取麥克風收音的限制故有專屬的 app )方式,讓志願者依照畫面的文字,以個人的自然語言唸一段文字敘述,以及幫助同聲計畫聆聽收錄的語音對照系統辨識出的文字進行校稿,透過兩種模式建構完整的語音資料。有興趣的朋友可前往同聲計畫網站貢獻一己之力:請點此
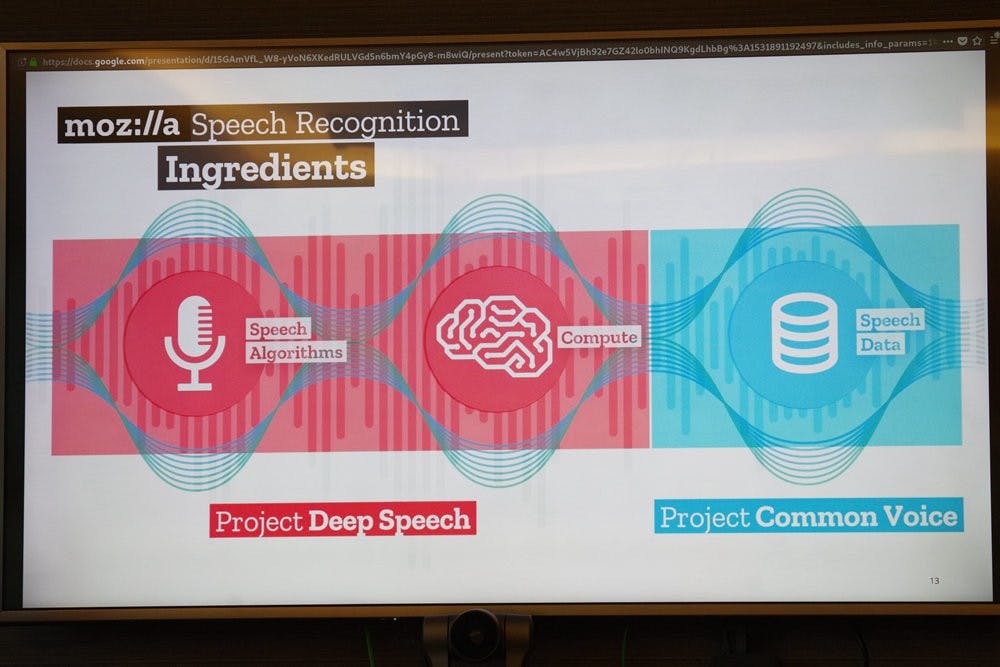
同聲計畫與深度語音辨識兩個開放專案的目的,旨在解決當前自然語音互動當中的前端處理,也就是當接收到使用者語音後,將其從聲音轉化為文字的過程,雖然乍聽之下不是太複雜的技術,但由於自然語言牽涉到口音、咬字等問題,要能正確將自然語音轉換為文字需要龐大的語音資料庫做為基礎,同時還要有將這些語音資料庫建立成辨識模型的能力。
然而取得語音資料庫並不容易,直接從消費者手中蒐集勢必牽涉隱私權問題,公用資料庫或是開源資料庫也會有使用權限方面的情形(例如不能商用化,或是只能在一定的條件下無償使用),往往要藉由商業方式購買,同時也要有 AI 專家建構辨識模式,但也因此,當前知名的自然語音辨識服務背後多被大型企業掌握;以標榜網路自由的 Mozilla 當然也希望打破這樣的僵局,以開源精神推出同聲計畫專案,終極目標就是成為全球最大開源語音資料庫。
除了蒐集語音以外,同聲計畫相當重要的一點就是要蒐集自然念出的語句,這也需要有配合的文字內容,這部分好像聽起來也很簡單,不過就與語音一樣還是會牽涉到內容是否能使用的問題,同時讓使用者念誦的文字也要是生活化的內容,像是文案、新聞稿、公告、詩集、古文等就不太合適了。
目前同聲計畫供貢獻者念誦的文字內容來自兩種,一種是自願者貢獻的內容,另一種則來自開放可合理使用的文字內容,當前的比重為各半;前者所提供的內容包括部落格、日記、詩集等形式,而開放內容就相當複雜,因為開放內容會牽涉到是否有特殊條件限制,像是台灣政府機關過去 20 年提供 18 種 Data Set ,但開放使用條件皆不同,有些也限制不得使用於營利,同聲計畫志工也需要去釐清使用權限。



同時,同聲計畫所蒐集的語音內容,也將作為深度語音辨識計畫的基礎,利用深度學習技術的方式進行模型培訓,建立能正確將語音轉為文字的模型;深度學習技術的實用化,讓現在訓練辨識模型更有效率,同時 Mozilla 也藉由與 Mycroft 、 Snips AI 、 Bangor University in Wales 等合作建構學習系統, Mozilla 利用四個 Node 的高效能 CPU + GPU 伺服器作為培訓用的主機,每個 Node 具備比 MacBook Pro 高出 45 倍性能的 GPU 、 10 倍的頻寬與 8 倍的記憶體。

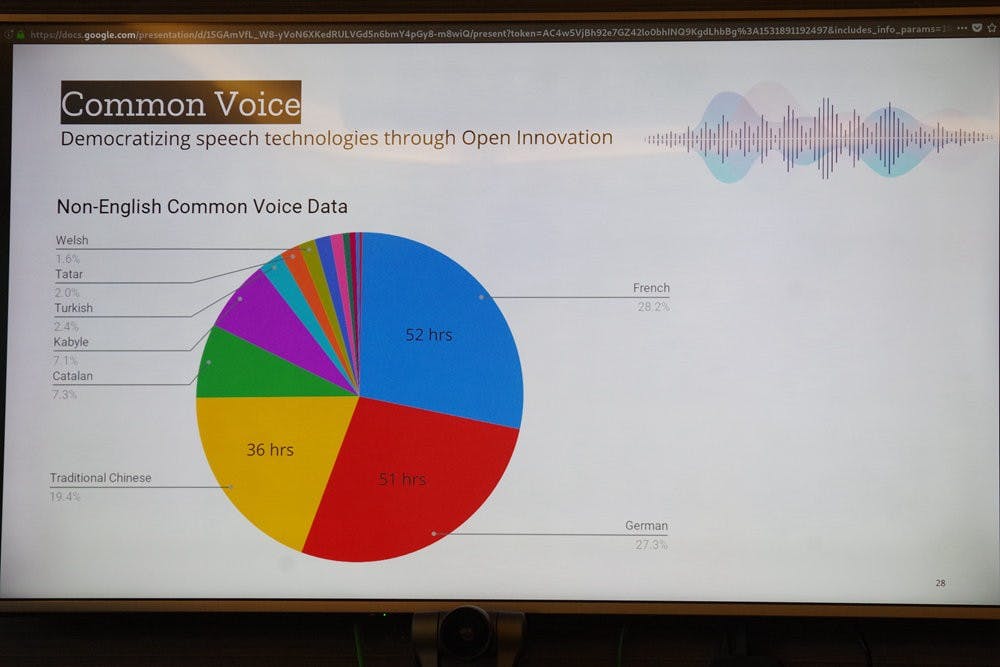
而在去年推出至今,同聲計畫已經有超過 900 小時的英文語音內容,且收錄者來自全球 112 國,同時也在近期開始蒐集其它語言,台灣慣用的正體中文亦成為第二波計畫中 15 種語言之一,也是當前唯一的亞洲語言,且驚人的是雖然正體中文雖較德、法與威爾斯語檔案還晚推出,不過在短短時間內已經迅速攀升達到 36 小時,成為同聲計畫當中英、法、德之外最大語音資料庫。

當然 Mozilla 的計畫不僅於此,它們的進程目標是蒐集達一萬小時的語音內容,同時希望第二波開始蒐集的語音資料庫能夠在今年內開放,此外目前已有 60 種語言的蒐集計畫在規劃中,不過也因此相當缺乏志工,畢竟同聲計畫都是靠有志的志工奉獻心力,像是台灣最為活躍 Irvine 本身也非 Mozilla 員工,而是響應這項計畫的志工,本業則是商業網站工程師。

根據 Irevine 的說法,台灣目前同聲計畫有 30 位志工,像是台灣的同聲計畫也曾在規劃中考慮羅馬、漢語拼音並行,同時也在規劃加入原住民語與台語等,只是受限於人力只能緩步進行, Irvine 與台灣 Mozilla 也希望呼籲能有更多志工加入行列,協助同聲計畫的擴大。另外在同聲計畫的規劃中,正體中文資料庫將與(也不確定何時會上線的)簡體中文資料庫分開,畢竟在文字的使用、語意表達等方式都不同, Mozilla 也希望藉由分離資料庫讓語音資料更合適用於當地的語言。
同聲計畫團隊當前除了陸續增加語音資料庫的建構,以及繼續達到蒐集百萬小時語音資料的目標外,也希望持續強化同聲計畫網站的設計,希望能讓貢獻語音的過程更為有趣。
















