
目前基於語音的語意辨識是相當廣泛的應用,不過唯有大企業才容易從使用者的手上蒐集資訊, Mozilla 本身也有語音與語意辨識相關的計畫,但由於體認到語音數據蒐集不易,雖曾使用開源資料以及商用語音庫,但由於語音與語意辨識需要自然語言而非朗讀型語音,訓練的結果效果並不理想,他們推出一個透過眾人之力蒐集語音數據並作為開源的計畫,稱為同聲計畫 Common Voice 。
有興趣成為語音數據資料提供者的志願者,可前往同聲計畫網頁:請點此

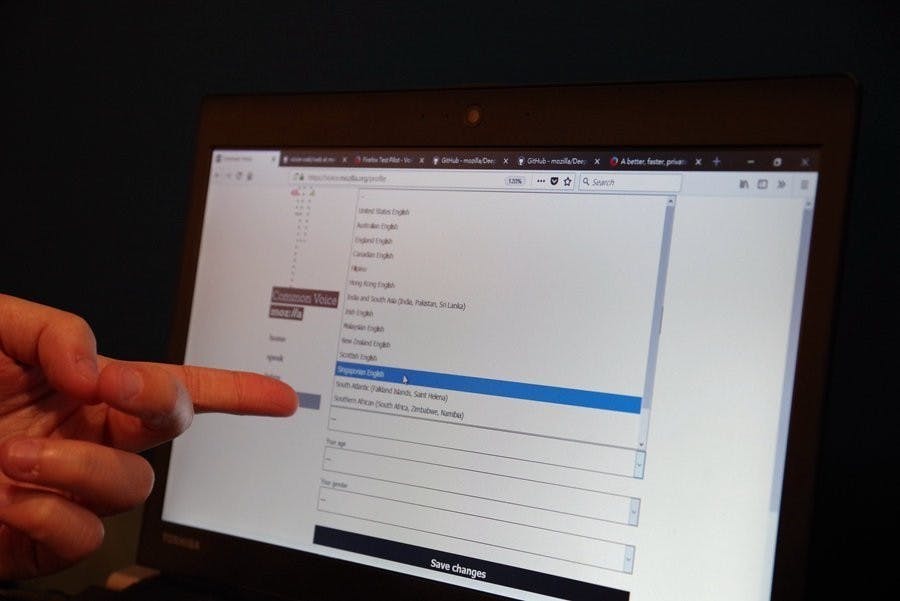
這項計畫目前先從英文資料庫建立起,讓志願者念出畫面出現的三個句子作為語音數據資料,同時志願者也可聆聽他人錄音的狀況檢視語音品質,最終希望能夠蒐集一萬小時的自然語音內容,而在系統中志願者更可選擇其國家語言形式,希望能透過此方式建立不同國家腔調的語音庫,提升未來作為深度學習訓練的時,使數據更精確。
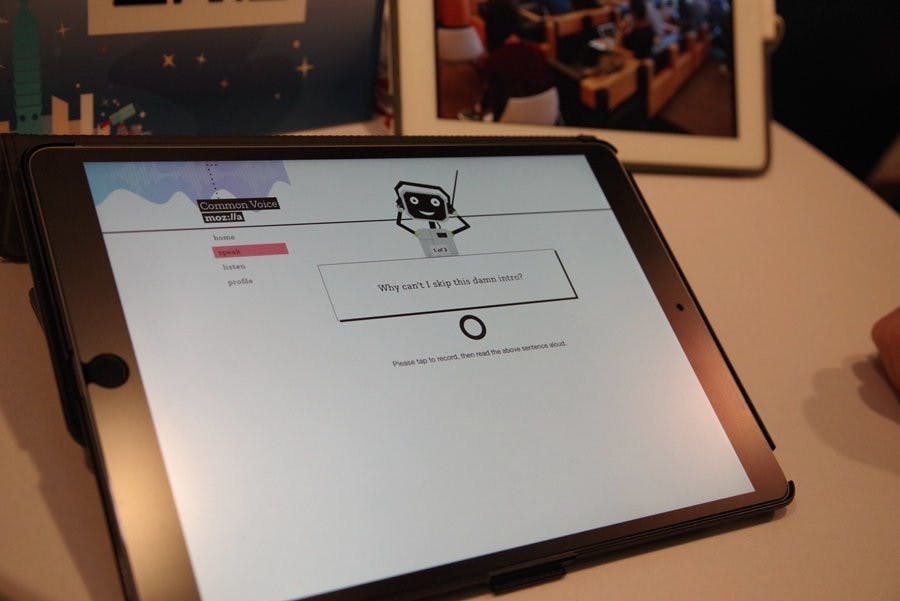
不過目前為止蒐集約 500 小時、由 13 萬人所提供 30 萬句內容,離目標的一萬小時還相當遠,而蒐集一萬小時語音內容的原因則是因為據 Mozilla 對深度學習的認知,一萬小時的內容才足以使自然語言辨識達到良好的效果;一如 Mozilla 計畫旨在創造開放的網路環境,同聲計畫所產生的資料庫也將會作為 Public Domain 使用。目前同聲計畫預計在第二季加入第二種語言,不過目前工作小組還在探討要加入哪種語言。
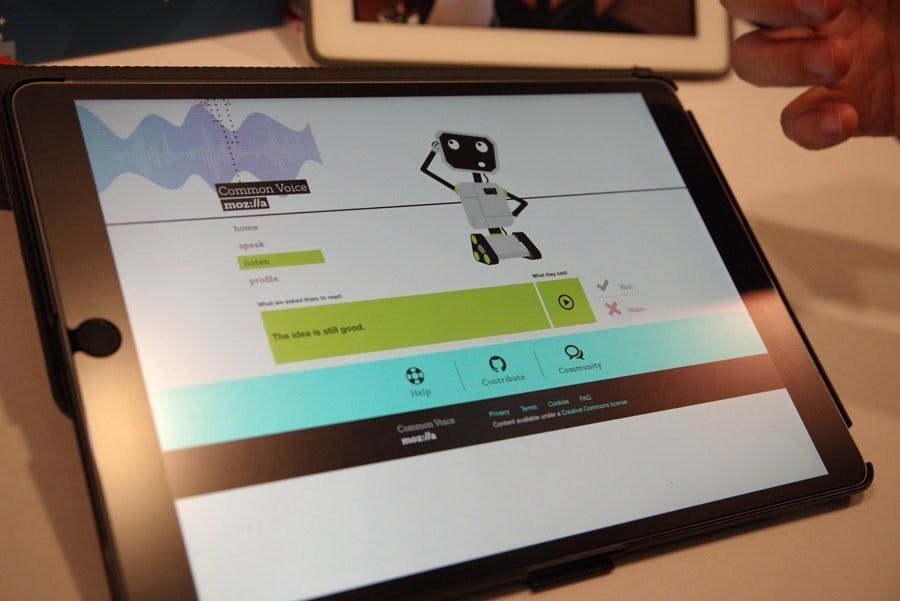
而 Mozilla 將會把同聲計畫的成果用於兩項領域,其一是做為 Firefox 語音輸入擴充套件 Voice Fill 的培訓數據,希望能使這項套件提升辨識率;其二就是結合源自百渡基於 TensorFlow 的自然語意辨識庫套件,將這些數據透過此語法在 Mozilla 的系統上進行自然語意的深度學習模型,而產生的模型成果也預計透過開放 API 的方式呈現。

Mozilla 同聲計畫志工 Irvine表示, Mozilla 在今年四月於台灣就舉辦過工作坊,探討如何透過新方式吸引使用者為同聲計畫貢獻語音數據,當時也罕見的吸引到在台灣舉辦各類工作坊以來最多的設計師,與與會的工程師呈現各半的情形,且當初本來覺得台灣會如歐美一樣以遊戲作為項目,但台灣開發者的創意卻出乎意料,他們多以社群互動的方式作為項目,例如卡拉 OK 等方式,這也是台灣開發者思維有趣的地方。

此外 Irvine 也是倡導網路健康環境的志工,他也介紹了多個 Mozilla 在網路上所提供介紹網路健康環境的影片與內容資源,希望更多人能夠瞭解到目前網路的情況,以及喚起使用者對於網路自由、個人隱私的意識。
有興趣觀看相關議題可到 Mozilla 網路健康專頁:請點此



















