
Tesla 在 Tesla 自動駕駛日的活動除了宣布下一代自動駕駛平台外,亦針對這套自行設計開發的平台架構進行深入的介紹, Tesla 自行設計的自動駕駛平台採用雙處理器設計,而每個處理器都是一顆具備完整功能、高度整合的 SoC ,採用 14nm FinFET 製程而非求最先進工藝應該也有降低成本的意圖。

Tesla 新一代自動駕駛平台的雙處理器架構是為了安全考量,以單處理器執行、另一顆處理器進行雙重驗證,並且兩邊採用獨立的供電進一步降低風險。每個處理器整合包括 CPU 、 GPU 、相機管理、影像解碼、記憶體通道,還有專屬的深度神經網路處理器架構,共使用達 60 億個電晶體。




這顆處理器的設計上, ISP 每秒可處理 1GP 畫素的數據,並提供 128bit 、 86GBps 的 LPDDR4 記憶體頻寬,影像編碼器相容 H.265 格式,另外除了車載級的安全管控外,還有 Tesla 設計、執行專屬代碼的硬體安全機制。

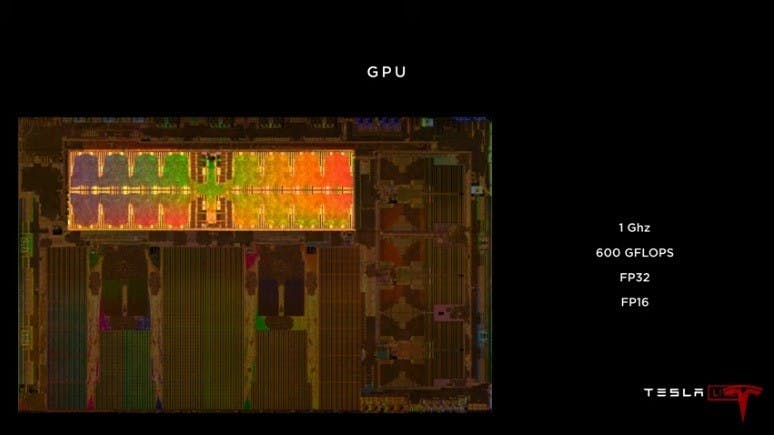
以 CPU 與 GPU 而言, Tesla 的處理器並稱不上高階的架構,搭載 12 核的 2.2GHz Cortex-A72 (註:當前 Arm 微架構已經進入 Cortex-A75 / Cortex-A76 世代),而 Cortex-A72 仍屬於 big.LITTLE 世代架構,故應該為 3 個 4 核心群組構成;另外 GPU 的時脈設定在 1GHz ,具備 600GFLOPS 性能,這部分的架構仍主要用於處理基礎底層系統。

而為了實現高效率的自動駕駛性能, Tesla 把重點放在硬體 AI 加速器上, Tesla 為這顆核心導入大面積的 NNP 深度學習神經網路處理器,具備 96x96 的乘法/加法陣列,配有 32MB 的 SRAM 等,在 2GHz 的時脈下可達到 36TOPS ,在搭載兩顆處理器的自動駕駛平台,能夠具備高達 72TOPS 的整體深度學習處理性能。

Tesla 的想法是高達 99.7% 的神經網路處理仰賴加法與乘法指令,故透過支援 32bit 整數加法與 8bit 乘法的 NNP ,可實現良好的 AI 性能,由於 AI 運算是即時處理,不需要把數據轉存到外部儲存,故 SRAM 的效率相當充裕,同時利用整合低功耗 32MB SRAM 可達到比 DRAM 少 100 倍的功耗。此外,為了龐大的外部影像感測器的圖片資訊,每個 NNP 有高達 1TB 的通道頻寬。



















