
NVIDIA 在台灣時間 22 日深夜發表新一代 AI 超算加速產品、代號 Hopper 的 NVIDIA H100 ,在產品特質上, NVIDIA H100 是 NVIDIA 自 P100 、 V100 到 A100 後的第四世代 AI 超算加速產品,也傳承自 P100 所建立的多項技術基礎,但同時為面對新一代 AI 技術與傳統運算需求, NVIDIA H100 不僅在架構設計持續精進,並借助合併 Mellanox 帶來的高速網路技術與第四代 NVLink ,使 NVIDIA H100 的性能有大幅度的提升。
稍早 NVIDIA 透過線上會議方式針對 NVIDIA H100 的幾項技術重點進行說明,不過若對完整技術介紹有興趣可閱讀 NVIDIA 官方部落格文章與下載白皮書。 Hopper 開發者部落格文章 、 Hopper 技術白皮書(此連結為下載連結)
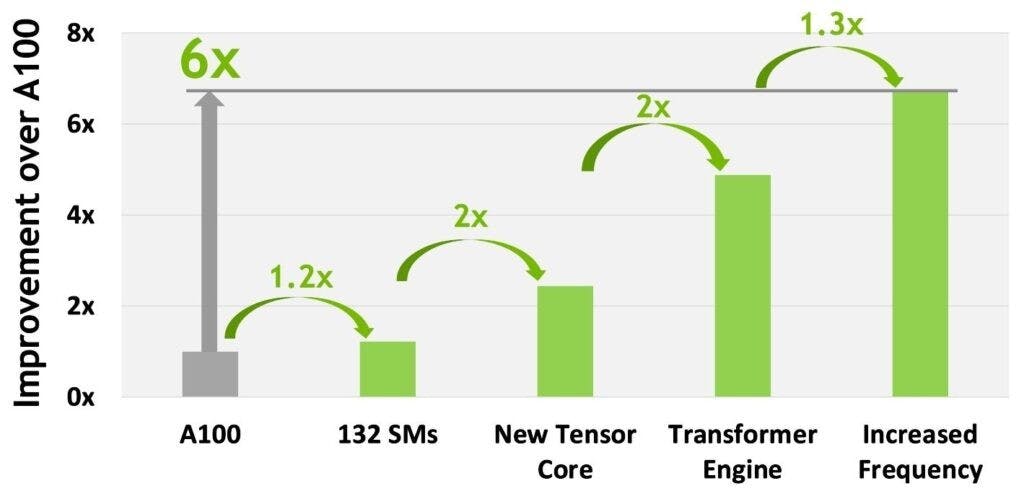
NVIDIA 在主題演講提到單一 NVIDIA H100 相較 NVIDIA A100 有 6 倍的運算性能提生,這並非單純依賴電晶體增加而來,而是結合架構與新技術得到的成果;受惠台積電 4nm 製程, H100 得以容納達 132 個 SM (完整晶片為 144 個)與更高的時脈,同時改良的第 4 代 Tensor Core 、新加入的 Transformer Engine 技術等,皆是使 H100 獲得突破性能提升的關鍵。
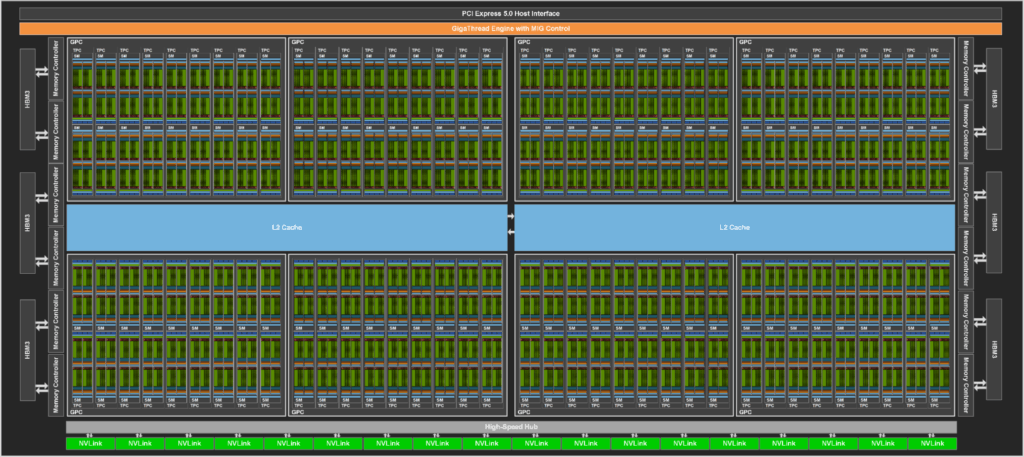
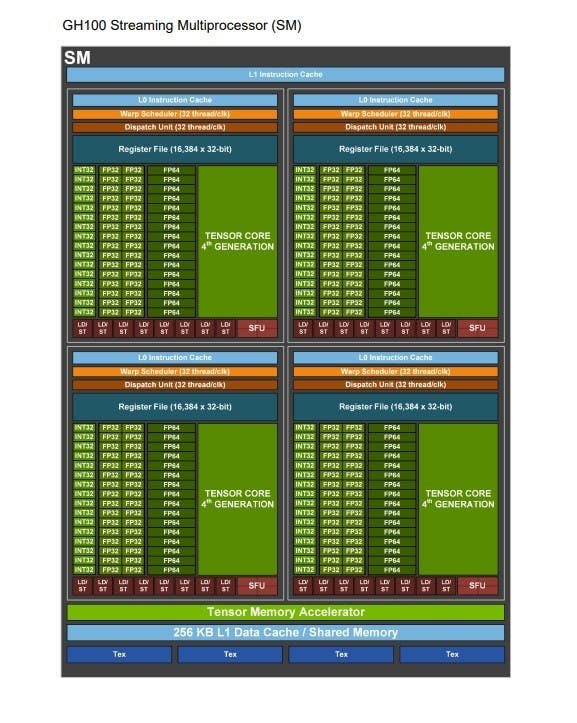
NVIDIA H100 基於 GH100 晶片,一個完整的 GH100 以 8 個 GPC 、 72 個 TPC 與 144 個 SM 構成,每個 SM 單元包括 128 個 FP32 Cuda Core ,意味著完整版 GH100 有高達 18,432 個 FP32 CUDA Core ,此外還具備高達 60MB 的 L2 快取,同時 L2 快取支援數據壓縮與解壓縮功能,對外通道則採用第 4 代 NVLink 與 PCIe Gen 5 。
在架構中, NVIDIA H100 不僅配有當前最高效能的新一代記憶體 HBM3 ( PCIe 版本則為 HBM2e ),提供高達 3TB/s 的頻寬,同時還具備 256KB L1 與多達 50MB 的 L2 快取架構,能站存多數的模型與數據供晶片重複存取,並減少反覆向 HBM3 存取資料的情況;此外,NVIDIA H100 也是全球首款支援機密運算的 GPU ,能夠進一步保護用戶的數據並防禦硬體與軟體攻擊,且可在虛擬化與 MIG 環境隔離與保護虛擬機。
Hopper 架構有幾項重要特色,架構所採用的第 4 代 Tensor Core 針對新一代 AI 與 HPC 工作具備更高的性能,亦加入全新的 FP8 加速,同時因應大型語言推論的 Transformer 技術,加入能夠自動判斷類型在 FP8 與 FP16 轉換的 Transformer Engine 。
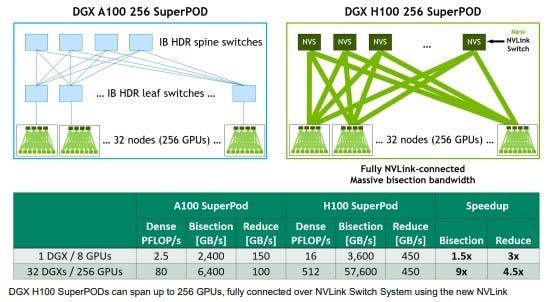
同時第 4 代 NVLink 不僅藉由 18 個第 4 代 NVLink 鏈路提供高達 900GB/s 的傳輸速度( A100 由 12 個第 3 代 NVLink 鏈路達 600 GB/s ),結合具備 64 個第 4 代 NVLink 的第 3 代 NVSwitch 內部交換器,可將節點中的 8 張 NVIDIA H100 SXM 構成一個大型 GPU 。同時全新的 NVLink Switch 外部交換器透過第 3 代 NVSwich 技術,能夠連接 32 個節點、 最多 256 個 GPU 以 2:1 椎狀拓樸,使連接的節點能以高達 57.6TB/s 的全頻寬連接,並達到 exaFLOP 等級的 FP8 稀疏 AI 性能。
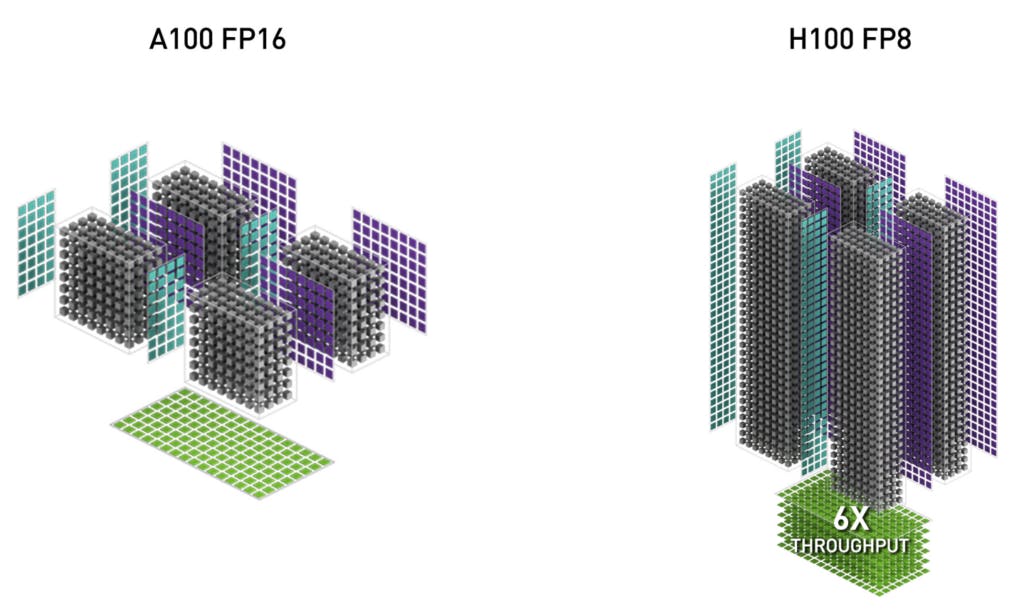
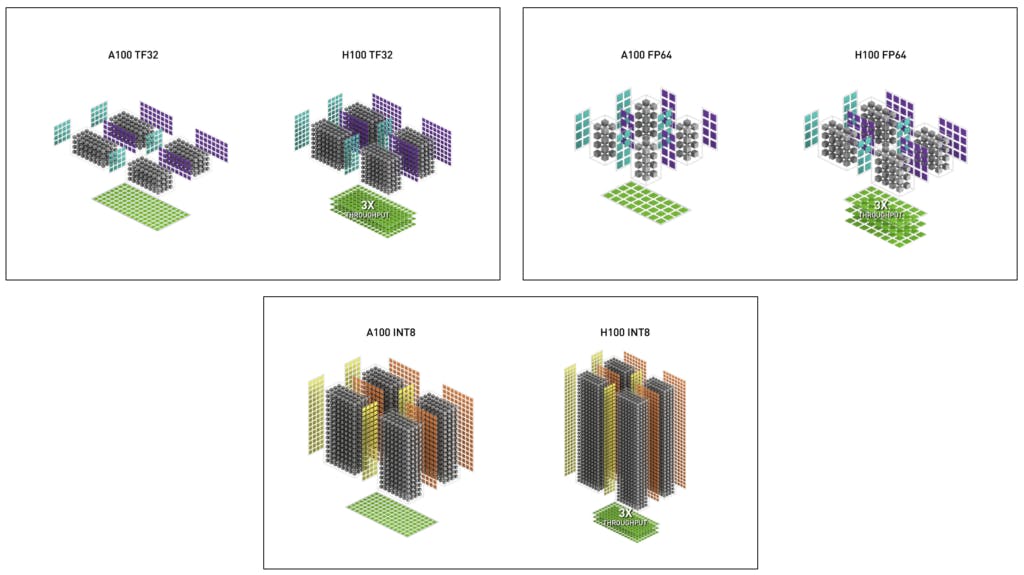
相較 A100 , H100 的第四代 Tensor Core 具備更多數量與更高的時脈,傳輸速度提高 6 倍,每個 SM 相較 A100 的 16bit MMA 的性能提升 2 倍,同時借助支援 FP8 大舉提升推論應用的性能。而在傳統運算也再度提升性能,受惠同時脈 SM 性能提高兩倍與增加更多 SM 單元,相較 A100 提升達 3 倍的 FP64 與 FP32 的性能,同時第 4 代 Tensor Core 也相較上一代具備更高效率的數據管理,能夠省下最多 30% 的作業傳輸能耗。
此外 H100 也支援多種嶄新的設計,像是能允許跨 SM 共享記憶體負載、儲存與 SM 對 SM 直接通信的分散式共享記憶體,還有包含 TMA 的全新非同步執行功能,此技術能使總記憶體與共享記憶體之間更有效率傳輸大數據塊。
當然提到 H100 在 AI 技術的新技術,就不得不提到上面提到的 Transformer Engine , Transformer Engine 是因應在大規模自然語言模型盛行的 Transformer 模型訓練與推論的軟體與硬體整合技術,能夠依據動態管理與選擇 FP8 與 FP16 ,並自處理模型每一層 FP8 與 FP16 的自動轉換,相對現行的 A100 架構,借助 Transformer Engine ,能使 AI 訓練提升 9 倍、並使推論能提升 30 倍,同時不影響精確性。
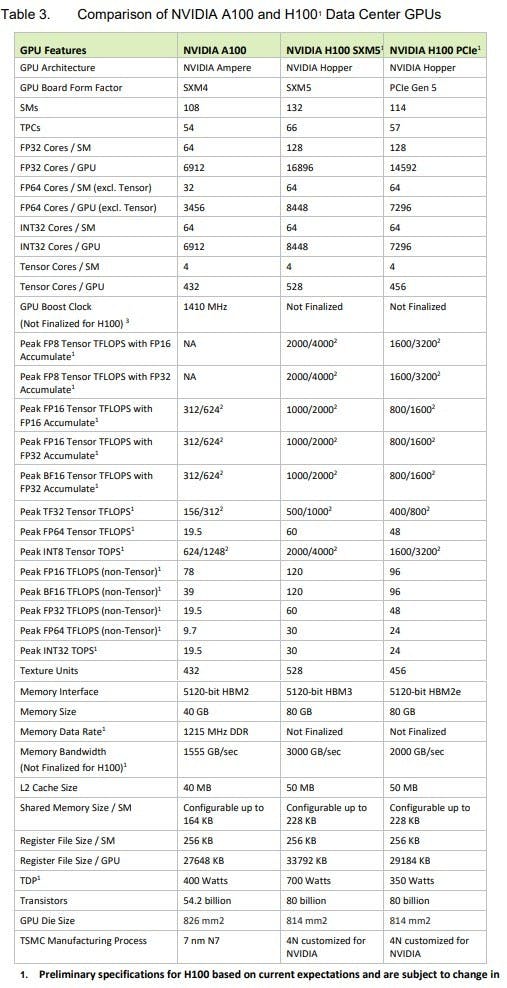
在主題演講當中, NVIDIA 提及 NVIDIA H100 提供 SMX 與 PCIe 兩種模組,雖然兩者基於同樣的 Hopper 架構,記憶體也同樣達到 80GB ,但除了介面以外還有不少細部差異,然而目前無論是 SMX 或是 PCIe 版本皆非完整的 144 個 SM 版本,或許完整版 Hopper 晶粒將會是用於建構 Grace Hopper SuperChip 。
SMX 版本的 NVIDIA H100 具備 132 個 SM 單元,而 PCIe 版本僅為 114 個,意味著兩者在包括 CUDA 核心、 Tensor Core 等的數量已有基本的區別,此外雖然記憶體容量皆為 80GB ,但 SMX 版為 HBM3 ,而 PCIe 版本為 HBM2e 記憶體,同時, SMX 版本的耗電達 700W ,而 PCIe 版本為 350W ;不過雖然 PCIe 版本的性能相對受限,但主要也是因應採用 PCIe 介面的通用設計伺服器架構做出的調整,採用 NVLink 連接的 SMX 模組則具有在散熱架構更高的彈性,也得以藉由更高的時脈運作。

縱使 NVLink 技術再強大, NVIDIA 仍提供 PCIe 版本的原因仍是因應市場需求,在執行長黃仁勳的訪談中提到, NVIDIA 是一家提供加速技術的公司,加速技術無論如何發展,一套完整的硬體架構仍須仰賴做為執行系統與分派工作指令的 CPU ,故 NVIDIA 需擁抱市場主流的 CPU 產品,雖然 NVIDIA 將在 2023 年推出基於 Arm 指令集的自主架構 Grace CPU ,但當前市場主流仍是 Intel 與 AMD 的 CPU , Intel 與 AMD 對第三架構則提供通用標準的 PCIe 介面,無論是 SXM 版本或是 PCIe 版本最終仍須透過市場主流的 PCIe 介面與 CPU 連接,但 NVIDIA H100 藉由率先支援 PCIe Gen 5 介面,與相應的處理器之間提供更高的頻寬。
















