
NVIDIA 首度公開 NVIDIA A100 搭配 Arm 架構 CPU 的效能表現,在最新 MLPerf 的基準測試結果證實無論是搭配 x86 或是 Arm 架構皆有出色的水準,證實 Arm 架構伺服器不僅有出色的能源效率,在搭配 NVIDIA A100 GPU 的異構運算同樣有出色的性能,這也是 MLPerf 資料中心類別首度於 Arm 架構系統進行測試,同時 NVIDIA 也連續三度在 MLCommons 推論測試基準創下效能與能源效率紀錄, NVIDIA 亦為唯一一家自第一輪起至今不間段公布 MLPerf 成績的公司。
此次公布 Arm 架構測試表現亦對 NVIDIA 往後的布局有重大意義,首先 NVIDIA 預計在 2022 年公布首款基於 Arm 指令級的伺服器級 CPU 產品 Grace , Grace 不僅是 NVIDIA 首度開發的 Arm 架構伺服器處理器,更重要的是針對 NVIDIA 的 GPU 加速特性如 NVLink 等提供支援,相較 x86 架構連接技術受制 Intel 與 AMD 的情況,並提供 CPU 對 CPU 、 CPU 對 GPU 的相互連接與記憶體共享等特色, Grace 有望進一步提高異構運算的核心溝通與記憶體規模。
另一方面,雖然目前受到諸多阻撓,不過 NVIDIA 仍努力朝向收購 Arm 為目標,一但 NVIDIA 成功與 Arm 合併,也意味著更多 Arm 架構伺服器製造商與新創能夠藉此跨足混合加速運算的行列,畢竟 NVIDIA 不僅只是在硬體架構提供對 Arm 的支援,同時亦在軟體部分進行深度合作,使所有基於 Arm 架構的處理器得以受惠。
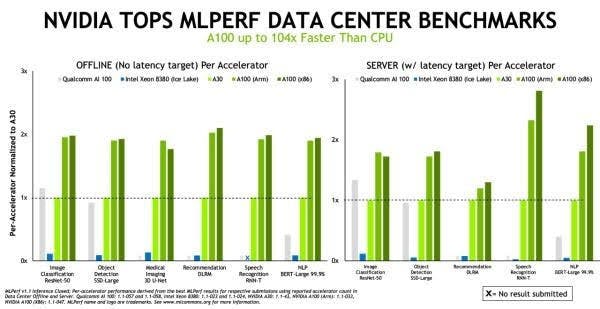
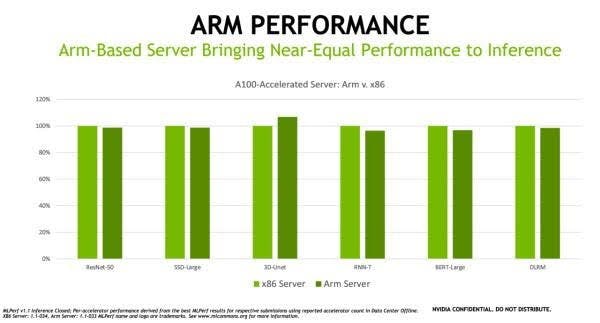
今年 NVIDIA 在 MLPerf 的七項推論皆取得領先,包括由 NVIDIA 與阿里巴巴、 Dell 、富士通、技嘉、慧與、浪潮、聯想、 Netrix 與美超微等九家生態合作夥伴打造的系統參與此輪的測試。此次最重要的即是有 Arm 架構處理器的伺服器參與測試,而在公布的結果當中,採用 Ampere Altra CPU 的 Arm 架構伺服器在同樣搭配 NVIDIA A100 下,有著幾乎等同 x86 架構系統的效能,甚至在其中一個項目出現領先。
不過如同 NVIDIA 所言,支援 Arm 架構處理器不代表 NVIDIA 要放棄 x86 ,而是因應當前市場有越來越多系統業者投入 Arm 架構的懷抱,畢竟 Arm 架構不僅近年效能提升並保有節能優勢,較 x86 多元的架構規劃也提供更豐富的彈性,由其 Arm 宣布 Neoverse 之後,又進一步針對伺服器應用提供更合適的微架構與功能。
且對於 NVIDIA 投入加速運算以來,除了硬體架構的持續發展,更重要的是也不斷在軟體進行最佳化與更多功能,例如 NVIDIA TAO 工具套件藉由遷移學習方式使訓練藍本基數較少的項目也能建立高精確的模型; NVIDIA TensorRT 軟體不僅針對 AI 模型最佳化與妥善運用記憶體,同時可支援 x86 與 Arm 架構系統;另外藉由不斷改善軟體堆疊,相較四個月前公布的 MLPerf ,以相同的硬體進行測試,效能提升 20% 、能源效率也提升 15% 。
此外, NVIDIA 也將進行測試基準的各項軟體開放到 MLPerf 資料庫,使任何有興趣的用戶皆可複製與重現基準測試結果, NVIDIA 也不斷將這些程式碼倒入深度學習框架與容器,並透過 NGC 開放這些新框架與容器。



















