
NVIDIA在2024年3月的GTC大會公布全新架構的Blackwell加速器,隨著Blackwell步入量產急將出貨,Blackwell首次於MLPerf Inference v4.1基準測試活動亮相,並在所有資料中心測試項目刷新紀錄,其中於處理MLPerf最大LLM工作量的Llama 2 70B,相較NVDIA H100 Tensor Core GPU高出4倍。

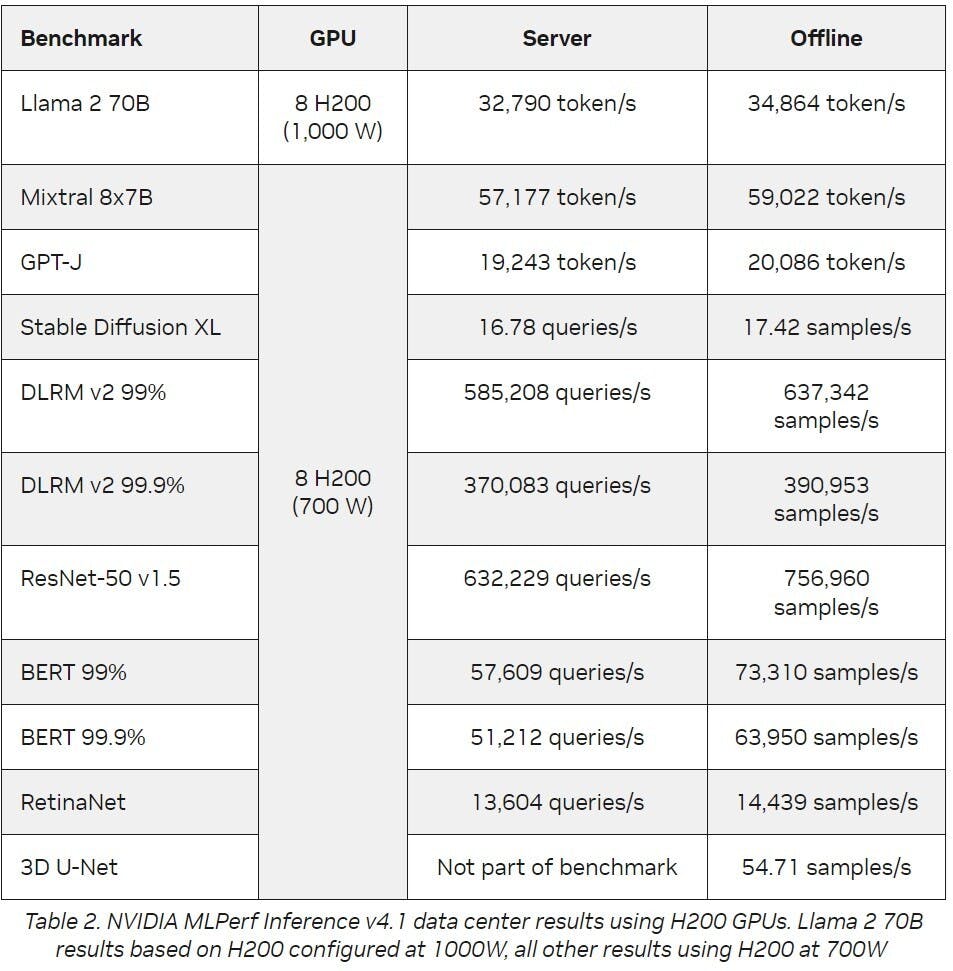
雖然Blackwell仗著新架構刷新各項紀錄,然而基於Hopper架構的NVIDIA H200 Tensor Core GPU也在此輪的於MLPerf Inference基準測試有亮眼的成績,在資料中心類別的各項測試裡均有著出色表現,包括新加入測試、有著467億個參數、每個token有129億個活躍參數的 Mixtral 8x7B 混合專家(MoE)LLM。MOE LLM具備單一部署回答多樣問題與執行多種任務,每次推論僅需啟動幾個專家,提供的速度比類似大小的密集模型更快。
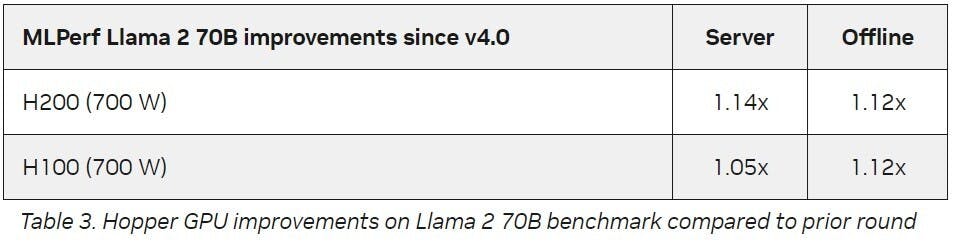

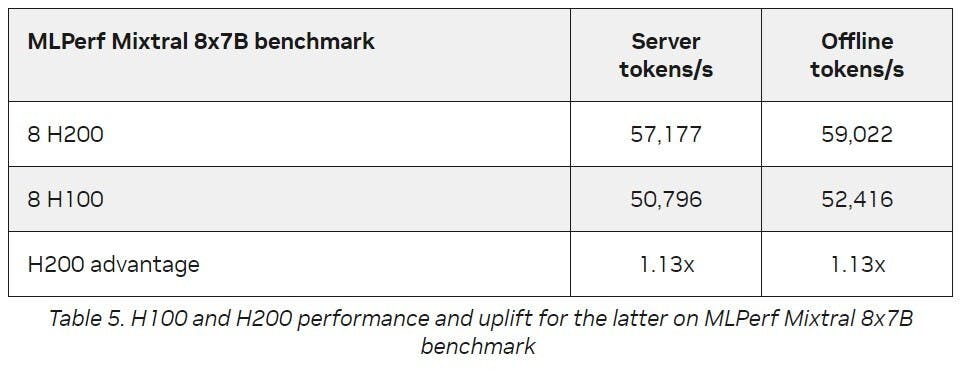

且NVIDIA透過平台一致性以及持續推陳出新的軟體最佳化,仍能使繼有的架構在生命週期不斷提升性能,以NVIDIA H200為例,在經過軟體更新後處理生成式AI推論的性能提高27%,顯示客戶在投資NVIDIA平台的長期附加價值。
而隸屬NVIDIA AI平台的Triton開源推論加速器可搭配NVIDIA AI Enterprise軟體使用,能協助組織將特定框架的推論加速器整合至統一的平台,可降低在生產環境佈署AI的總持有成本(TCO),並將佈署模型的時間自數個月縮短為數分鐘,在這一輪的MLPerf測試,Triton推論伺服器的性能幾乎等於NVIDIA裸機測試結果,意味著企業不需在功能豐富的生產級AI推論伺服器與達到高峰值吞吐量取捨。
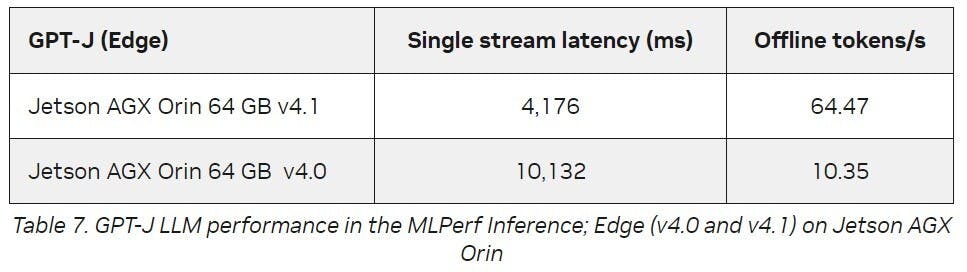
NVIDIA的AI技術也同樣在邊際大放異彩,適用於邊際AI與機器人的NVIDIA Jetson平台可執行任何類型的本地端模型,諸如LLM、視覺Transformer模型與Stable Diffusion,在此輪測試中,NVIDIA Jetson AGX Orin系統模組處理GPT-J LLM工作負載較前一輪傳輸量提升6.2倍、延遲改善2.4倍,使開發者能透過此模型於邊際裝置提供與人類透過自然語言流暢溝通的體驗。



















