
照片為廣達預計於今年內推出、搭載 Tesla P100 GPU 的伺服器 GPU 陣列主機版
原本因運算力停滯的深度學習架構,在基於 GPU 加速的平行運算發展成熟之後也漸成顯學,從搜尋、辨識到日前 AlphaGo 在圍棋領域打敗人類,再再都證實具學習力的深度學習架構的價值;而 NVIDIA 也堅信新一代的 Pascal 架構將會使深度學習的發展有更飛躍的突破,因為 Pascal 架構的設計可說是多方針對深度學習所需的運算效能做了相當大的創新設計。
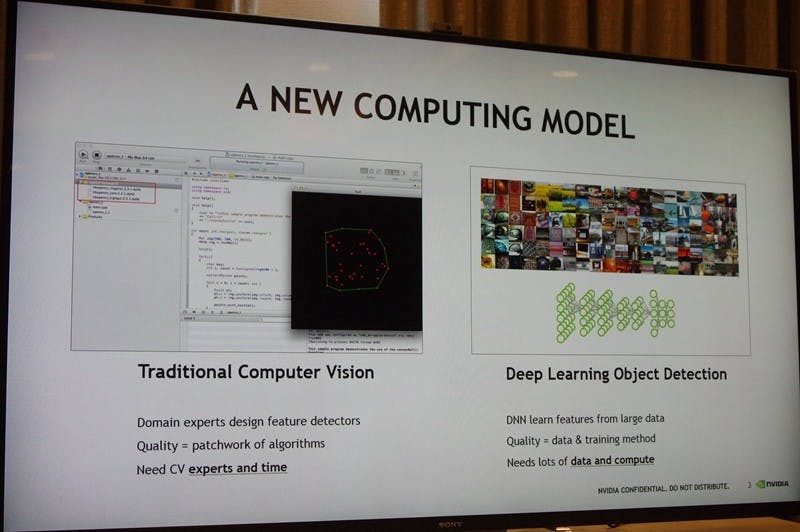
相較傳統的人工智慧邏輯,深度學習仰賴的不再是撰寫邏輯演算法的專家與撰寫邏輯時間,而是需要海量的資訊作為學習基礎,同時透過高效能的運算力處理這些學習素材,故在深度學習趨勢下,透過 GPU 加速是勢在必行。
Pascal 除了在基本架構重新設計外,使 Pascal 相較過往用於深度學習更有效率的原因,則在於全新的溝通模式與傳輸通道,藉由與 IBM 共同開發的 NVLink 技術,不僅有超越 PCIe 的頻寬,同時也實現 GPU 之間的直接溝通,並使統一記憶體技術得以實現,各個 GPU 可直接存取彼此的 RAM ,使得同樣位於 NVLink 上的 GPU 可視為一個大型 GPU ;若搭配支援 NVLink 的 CPU 如 IBM Power 8 ,更可使 GPU 與 GPU 進行雙向溝通。另外 HBM2 記憶體的導入,可大幅縮減 GPU 與記憶體溝通的時間,相較傳統的 GDDR5 甚至帶來 10 倍傳輸效率的增長。

雖就目前來看, Pascal 與 x86 CPU 仍需透過 PCIe Gen.3 溝通,但除了與 NVIDIA 密切合作的 IBM Power 以外, NVIDIA 也透露有數家基於 ARM 架構的伺服器晶片廠商對於 NVLink 有相當高的興趣,對於基於 GPU 加速的下一世代超級電腦,或許也會因為短時間內 x86 不支援 NVLInk 而導致未來對於 x86 的重度依賴產生變化。
但也因為 Pascal 帶來的架構的變化較大,除了像是 Google 、百度等自定義伺服器架構的服務商,以及 NVIDIA 所推出的 DGX-1 深度學習伺服器以外,伺服器品牌商搭載 Tesla P100 加速器的伺服器多數會在明年初推出,不過像是廣達則透露它們搭載 Tesla P100 的主機則最快七月就可供貨。




廣達的 Tesla P100 伺服器架構也相近於 DGX-1 ,同樣搭載高達 8 張以 NVLink 連接的 Tesla P100 與搭配兩顆 Xeon 處理器,也同樣採用 3U 設計,不過因應客戶的不同需求,廣達的伺服器並未採用全 SSD 設計,仍採用傳統伺服器常見的熱插拔硬碟設計,同時 GPU 散熱架構相較 DGX-1 所展示的設計也較接近傳統伺服器以大型風扇帶動散熱的設計,而非 DGX-1 號稱使用高階散熱材料搭配風冷設計。
你或許會喜歡



















