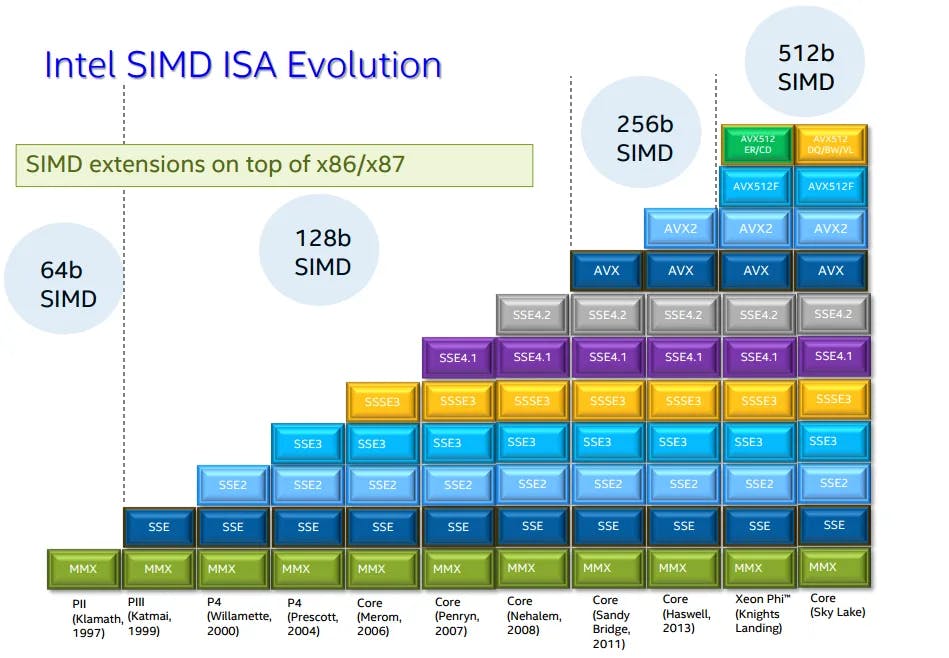
前情提要:淺談x86的SIMD指令擴張史(中):SSE2到SSE4。x86指令集的SIMD擴充,從1997年的MMX一路「堆積」到2008年的SSE4.2,看似已功德圓滿,但其實仍遠遠不足,累積缺陷總計如下:
- 雙運算元(A = A + B)的宿疾還是沒有解決,限制單一指令的功能,也變相增肥程式碼。
- 只要處理器的微架構足以負擔,可以一次處理的資料量還是是多多益善,越寬越好。
- 16個暫存器還是太少,人家古老的RISC可都是32個起跳的。
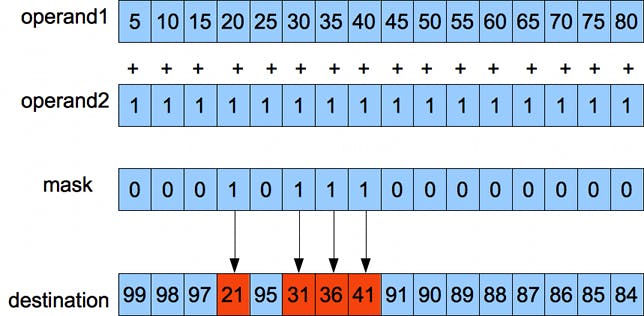
- 和真正的「向量(Vector)處理器」相比仍有差距,例如缺乏指定SIMD中需要被處理資料的遮罩(Mask)暫存器。
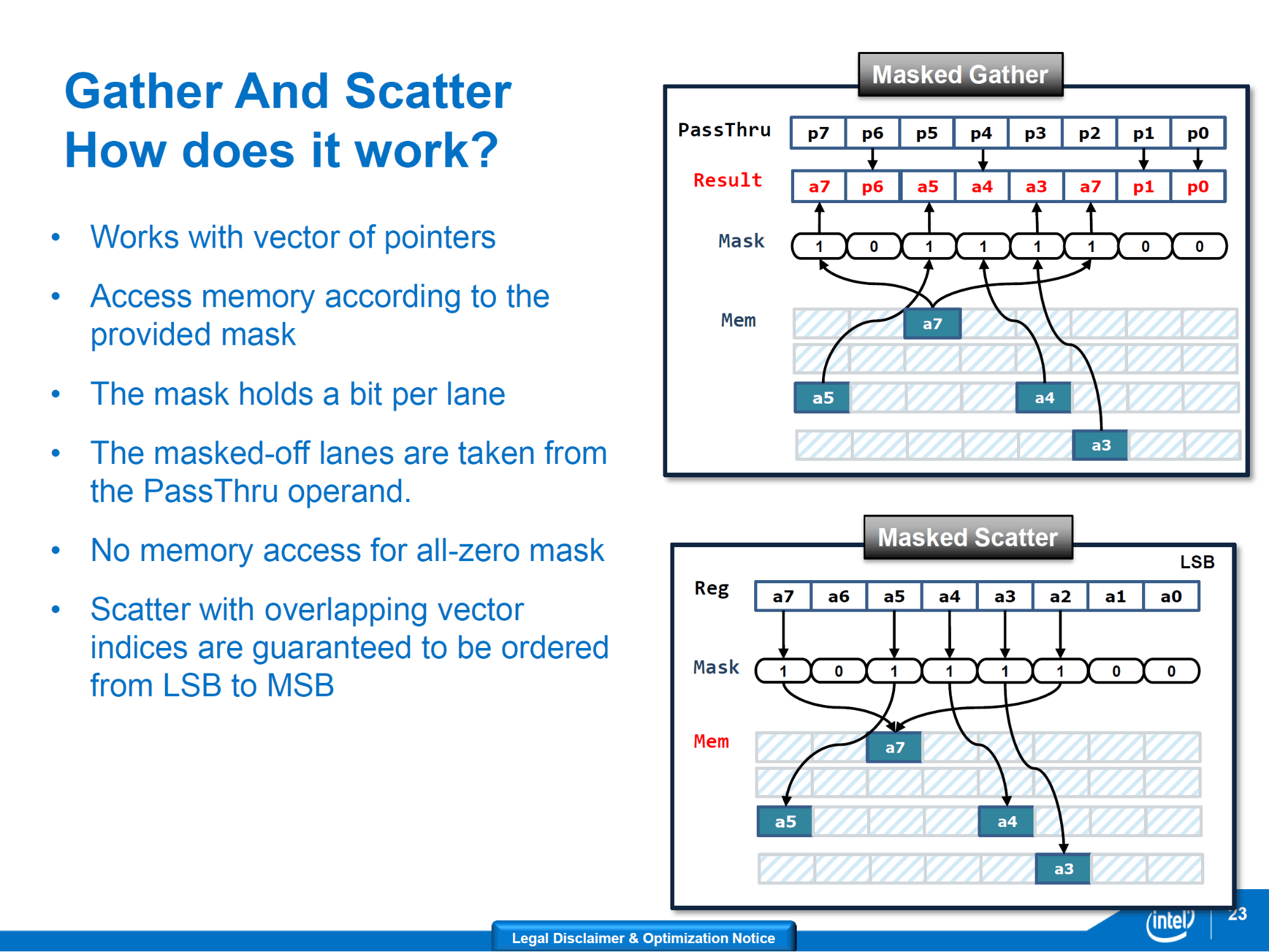
- 欠缺從散落在記憶體各處的運算元素「聚集(Gather)」至向量暫存器內,運算結束後再一次性「分散(Scatter)」送回記憶體四處的特殊能力。
- x86指令集的編碼問題,起碼對64位元模式來說,依舊存在。
AVX:史上最重要的x86指令集擴張 沒有之一
即使沒有白紙黑字的證據,筆者絕對有充分的理由相信,這就是Intel傳說中「Yamhill」的原貌,如果64位元x86指令集一開始就這樣弄,不要放任AMD胡搞瞎搞,該有多好啊。
在2011年的Sandy Bridge登場的AVX(Advanced Vector Extensions)堪稱面面俱到的傑作,不僅一口氣整合了過去x86指令編碼中的「麻煩製造者(Escape、SIMD Prefix)」,將所有可能影響指令編碼長度的資訊,集縮在指令前端的VEX(Vector Extension),大幅精簡指令編碼格式,無須讀取大半個指令,即可知道「這指令到底想幹什麼」,簡化指令擷取單元和解碼器的優化手段,並徹底針對SIMD運算最佳化,將128位元的XMM擴充成256位元YMM暫存器,實現「三運算元(如A = A × B + C)」指令兼具保留四運算元的擴充彈性。

一舉推翻SSE家族的AVX大革命
相信眼尖的科科勢必察覺到「偉大的可能性」:
既然AVX實際上與SSE共用暫存器,VEX內又包了過往SIMD指令需要的欄位(”mmmmm” 代表Escape、”pp” 則是SIMD Prefix),那創造「相對應SSE、指令解碼效率更快的AVX指令」又何嘗不可呢?
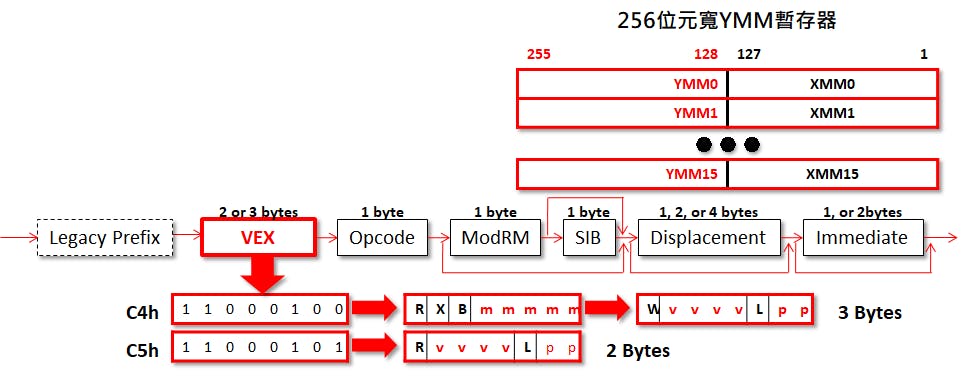
事實上,Intel的確一開始就打算「新瓶裝舊酒」:使用VEX編碼、運算元變成「YMM暫存器的下半部(上半部歸零)」的「AVX-128」,作為SSE的完美替代品(但MMX就無緣雨露均霑,畢竟沒和AVX共用暫存器),而Intel也鼓勵軟體開發者盡快用AVX-128替換SSE,設計處理器微架構時「讓常跑的工作跑得更快」,集中資源加速VEX編碼指令,便於用更低的成本打造出性能更好的產品,如投資更多的解碼器,提高每個時脈週期可完成解碼的指令數量。
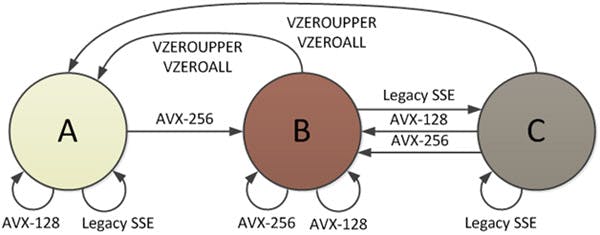
況且,一旦程式碼混合AVX和SSE,會因為「SSE指令並不會知道XMM暫存器多長了一截」,從執行AVX轉向SSE指令前,Intel處理器要先硬體儲存YMM暫存器高位128位元的內容,轉回AVX時再恢復,而發生類似昔日MMX和80x87浮點交互切換平白耗費幾十個時脈週期的慘況,「AVX-128」卻沒有這樣的困擾,Intel當然希望SSE完全被AVX替換掉。
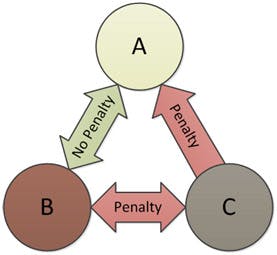
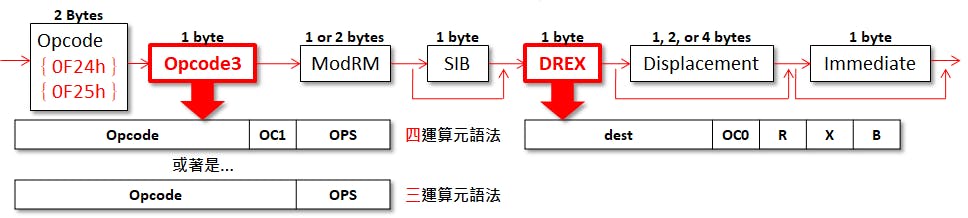
反觀AMD卻重蹈x86-64的REX覆轍,讓SSE5再度變成「化外之民」,指令解碼器需一路「爬」到DREX,再和Opcode3的內容「配對組合」後,才能確定暫存器號碼與順序,明顯不利產品實作。還好AMD沒真的悶著頭硬幹SSE5,讓推土機也乖乖的跟進AVX,只不過AMD到了Zen2才紮紮實實的提供「貨真價實」256位元寬的AVX執行單元,效能不再打對折。
暫存器長度和數量再度倍增的AVX-512
2013年Haswell的AVX2補足了運算元聚集指令,將大多數整數運算擴充到256位元,也具備了累積乘加運算(FMA,Fused Multiply-Add)。但這還不夠。在2013年隨著「Larrabee後代超級多核騎士團」Xeon Phi x200系列「Knights Landing」的AVX-512畢其功於一役,藉由指令編碼中的加強版VEX(Enhanced Vector Extension),一口氣達陣以下里程碑:
- 定義512位元寬的ZMM暫存器,YMM的再延伸。
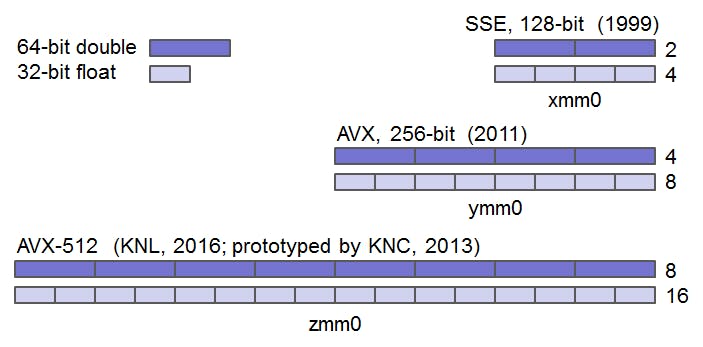
- SIMD暫存器倍增到32個,暫存器總資料量增加4倍。
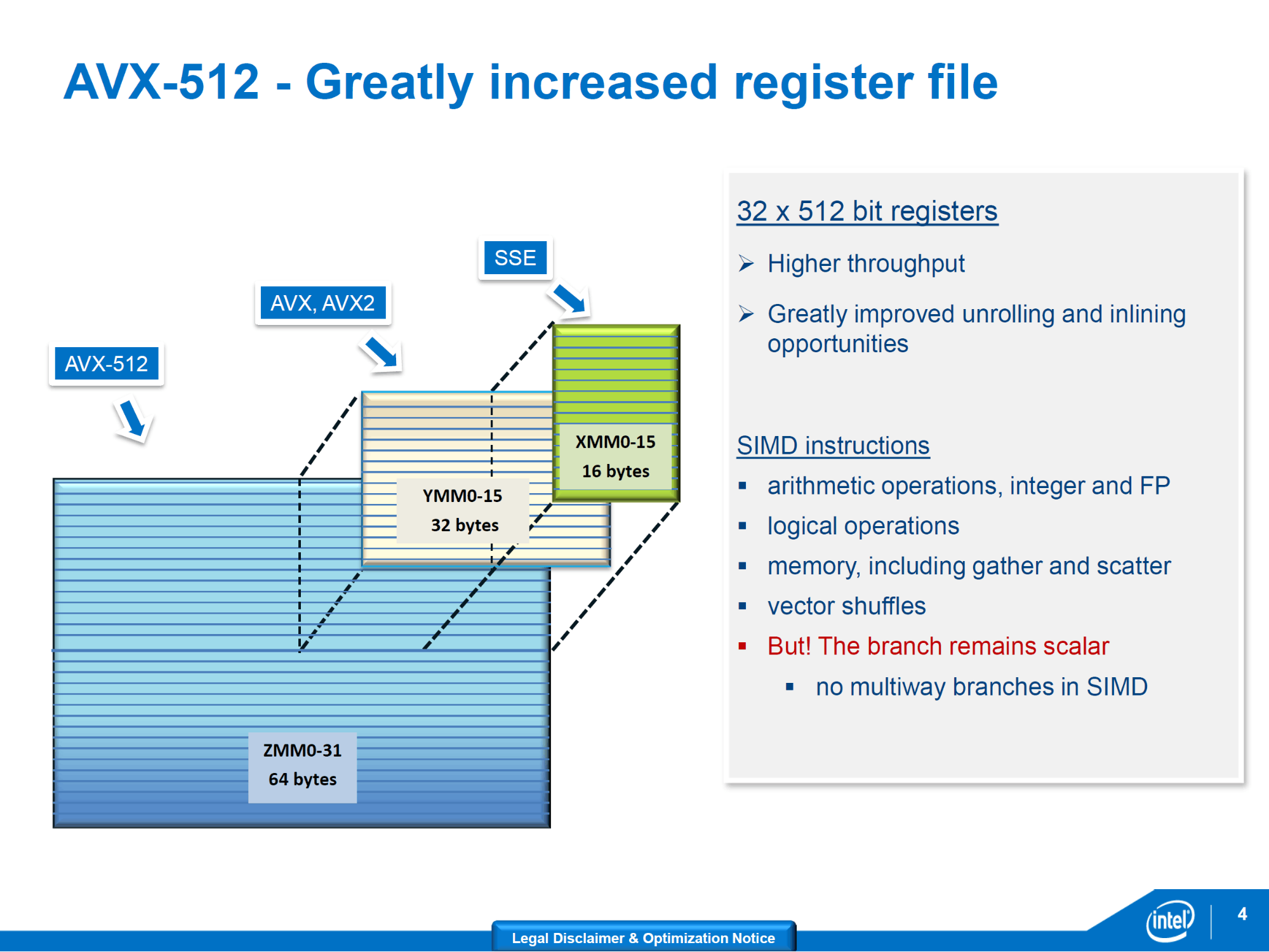
- 四運算元指令(像A = B × C + D)。
- 8個向量遮罩暫存器。
- 運算元聚集與分散指令。
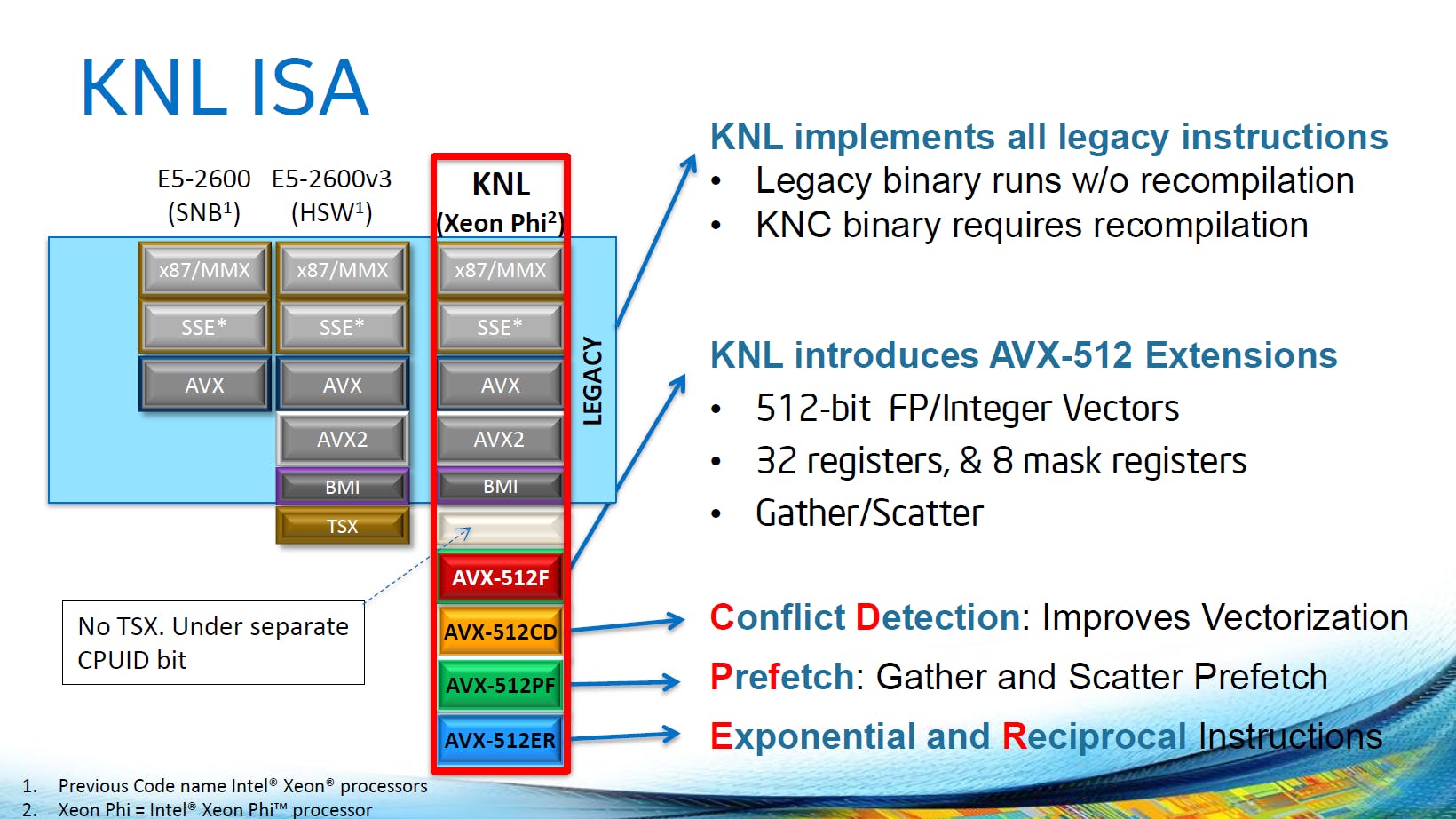
猜猜看AMD何時支援版本混亂不堪的AVX-512
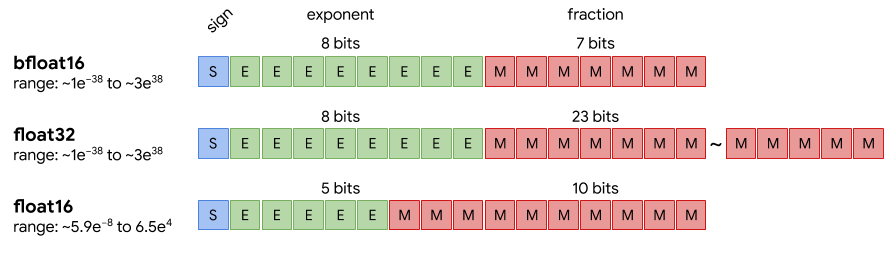
雖然Intel已經中止Xeon Phi產品線,但AVX-512仍將繼續發展下去,2020年的Cooper Lake將會跟著Google的腳步,對應指數小於FP32而動態範圍維持不變的BF16(bfloat16)浮點格式,提高「人工智慧應用的競爭能力」。


")
")
到底有什麼不一樣?")

")
")
")
")
")









