
受到 NVIDIA 先期投入市場的軟硬體優勢, AMD 的 Instinct MI200 加速器系列雖獲得美國橡樹嶺實驗室新一代超級電腦 Frontier 採用,但市場討論度則仍較 NVIDIA 來的少;不過 AMD 也正努力的持續自軟體與硬體兩方面強化,根據 MosaicML 公布的部落格文章, AMD 的 Instinct 250 在 PyTorch 2.0 與 ROCm 5.4 的雙重加持下,已有著趨近 NVDIA A100 的效能,同時不須針對 AMD Instinct 修改代碼即可進行大型語言模型 LLM 訓練。
MosaicML 的官方部落客表示其軟體 MosaicML 可為 NVIDIA 與 AMD 提供包括 FP16 、 BF16 的支援,使其具備機器學習與大型語言模型訓練的強化,且不需更新任何代碼;最新版本的 MosaicML 更進一步釋放 AMD Instinct 加速器的性能。MosaicML 指稱, Instinct MI250 在進行 MPT-1B LLM 模型可在同一個檢查點呈現與 NVIDIA A100 幾乎相同的損失曲線,且由於 AMD 透過 ROCm 替代 CUDA 、 RCCL 替代 NCCL 等條件,不須變動代碼,甚至可在訓練過程於兩種架構切換。
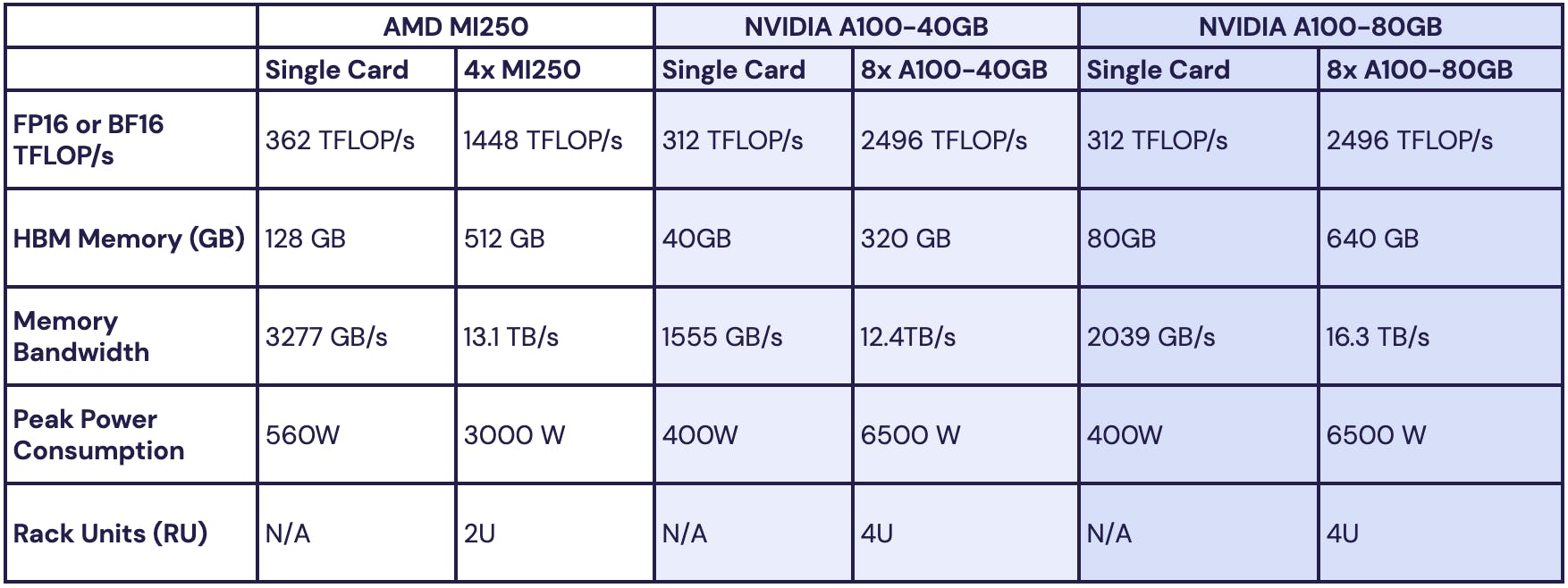
以 Instinct MI250進行 MPT 的 1B 至 13B 參數訓練吞吐比較時, MI250 系統的每 GPU 吞吐量約莫為 NVIDIA A100 40GB 的 8 成、 NVIDIA A100 80GB 的 73% ,效能則分別達到 94% 與 85% ,雖未達 1:1 效能,不過 MosaicML 相信隨著 AMD 持續改善 ROCm 軟體,彼此的效能差距能進一步縮減。
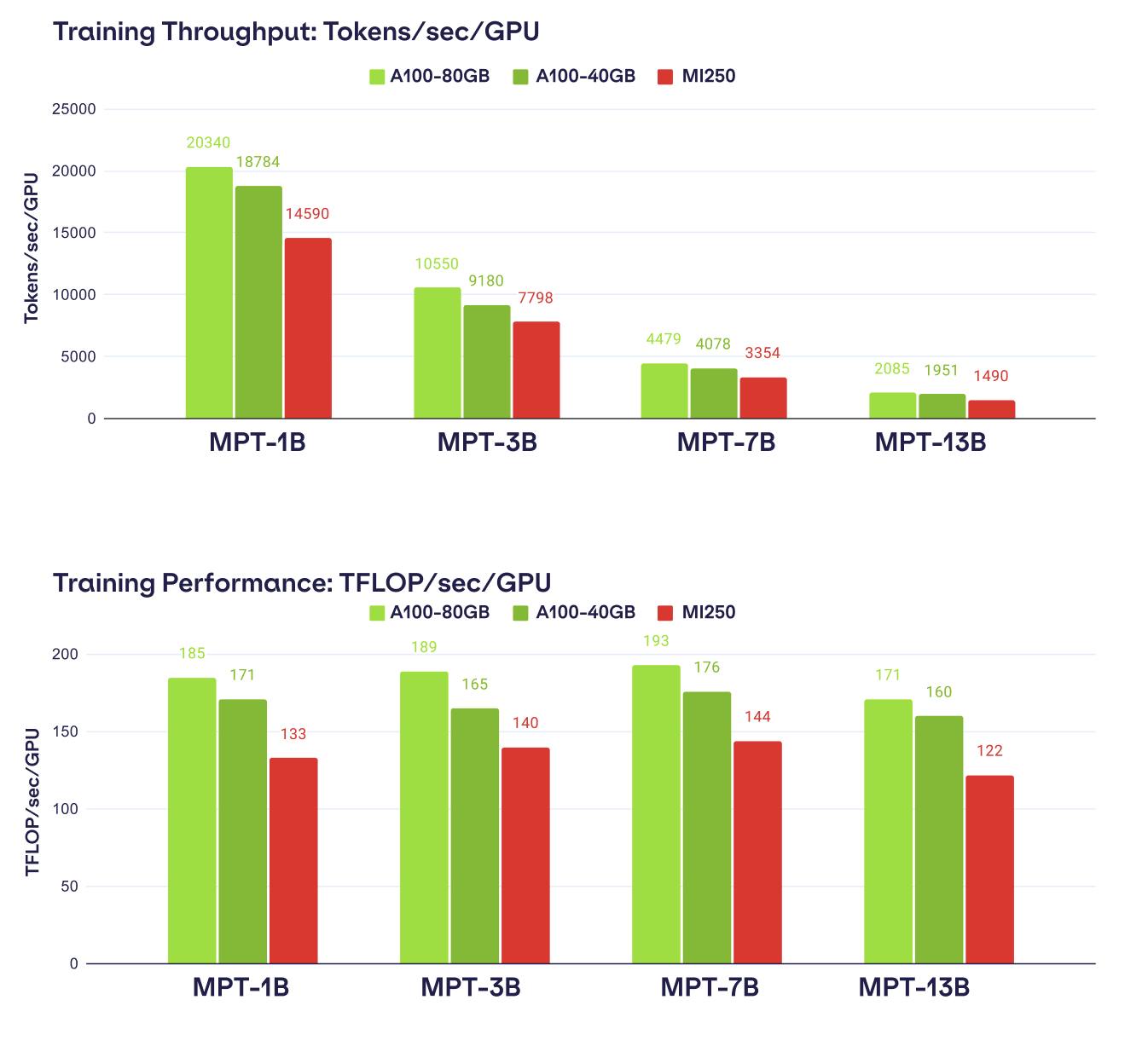
雖然 AMD Instinct MI250 在 FP16 效能、高達 128GB 的記憶體容量與 3,277GB/s 的記憶體頻寬等先天體質都勝過 NVIDIA A100 (畢竟晚了 NVIDIA A100 才上市),但回到系統建置考量, NVIDIA A100 在單一 4U 系統能夠擴充到 8 GPU , Instinct MI250 僅為 2U 型態最高 4GPU ,故單一系統的最高效能仍難以追上,或者是在需要相近層級的效能時,使用 AMD 加速器需比起 NVIDIA 加速器購買多一倍的系統。
然而,畢竟 NVIDIA A100 已是前一代產品,隨著 NVIDIA 新一代的 NVIDIA H100 系統陸續推出,現在 AMD 可能要寄望 Instinct MI300 能夠借助更龐大的記憶體與之一搏。但即便 AMD Instinct MI300 可進一步擴充到 8GPU , NVIDIA 以更進一步透過高速網路串接更大量的 GPU ,恐怕只論效能的最大化以及市場呼聲, AMD 也還仍需苦苦追趕;只是從市場的角度, AMD 應該有望取下一部分性價比導向以及不願看到 NVIDIA 獨大的系統訂單。



















