
自從2006年底至今超過十年的「通用運算導向」GPU,包含NVIDIA G80、AMD GCN、Intel HD Graphis Gen9、PowerVR Series 6、ARM Bifrost後的「SIMT (Single Instruction, Multiple Thread)」徒子徒孫,其獨樹一幟的運算架構,究竟應該如何從傳統的計算機系統結構去定義,一直眾說紛紜,這亂象從諸多「資深技術編輯」遍佈各家媒體的雞同鴨講,即可略見一斑。

- 純MIMD:這是NVIDIA剛發表G80時的主流觀點,反正也不必分什麼Vertex Shader和Pixel Shader,也不用管「顏色 (RGB三原色 + Alpha半透明通道)」或「位置 (XYZ + W遠近參數)」的四筆資料長的怎樣,就打散全部運算工作,通通丟給一大堆獨立的純量 (Scalar) 處理器「塞好塞滿」,所以近似傳統多處理器的MIMD。
- 其實「拆散運算,分而治之」是充分理解SIMT前很重要的認知,但這觀點卻忽略了「如何簡化軟體開發」與「充分利用運算單元」的因素,更絲毫看不見多執行緒的影子。如果GPU只是貨真價實的MIMD,那CUDA也不可能享有今日的成功,所以絕對是不及格的,也無法充分解釋為何GPU沒有傳統汎用CPU的快取資料一致性需求。
- 純SIMD:拜某本重量級計算機結構教科書的第五版,將GPU與向量電腦、SIMD指令集相提並論之所賜,「軟體開發者可延續既有循序性思考,亦可藉由資料階層平行化,提昇運算效能」並「可單指令啟動多筆資料運算,比起每道運算都需要執行一道指令的MIMD享有更多潛在的能量效率」的SIMD就變成思考GPU本質和優勢的出發點,而由「由數個多執行緒架構的SIMD處理器,所組成的MIMD多處理器環境」,只是一層無足輕重的外皮。
- 至於該如何釐清「如紡紗機般千絲萬縷的執行緒」如何被有效的執行,全部推給硬體執行緒排程器,就一句話打死了,根本看不出SIMT和被「外掛」同時多執行緒的SIMD有什麼差別。
- 講白了,扛出這種「正統計算機結構」觀點的文章作者,只是大腦發懶隨便東施效顰教科書觀點就隨便打發讀者騙騙稿費罷了,可能還會被朋友酸「你寫出來的東西根本就是Intel IBM眼中的GPU」 (為何筆者現在覺得臉腫腫der)。
- GPU宗教狂信者:我那管那些有字天書般的基本學理,反正這年頭的高效能處理器,只要掛上GPGPU甚至「人工智慧晶片」之名,就可超越一切物理限制和技術瓶頸,昇華成藐視「落伍」CPU的至高存在。被問到道理之所在?萬變不離其宗那101句「GPU就是生而高平行化所以天下無敵呀」。下面呢?就像紀曉嵐碰到太監,下面沒有了。
- GPU的「得道」,造就了「雞犬升天」的不學無術光華牌工程師等級「超時代計算機結構理論大師」,甚至從未聽聞一般大學計算機組織結構和計算機圖學使用的英文教科書,你跟他堂堂正正陳述正確的基本觀念,他們不但完全聽不懂,搞不好還會嗆你在蓄意賣弄學問。
- 很不幸的,資訊媒體圈一直不乏這種「大師」,他們的鼎鼎大名,也隨著網路媒體普及間接導致傳統電腦雜誌市場的崩盤,消逝於搜尋引擎的盡頭。
那SIMT究竟是什麼?在抽絲剝繭之前,我們先從SIMD的缺點談起。
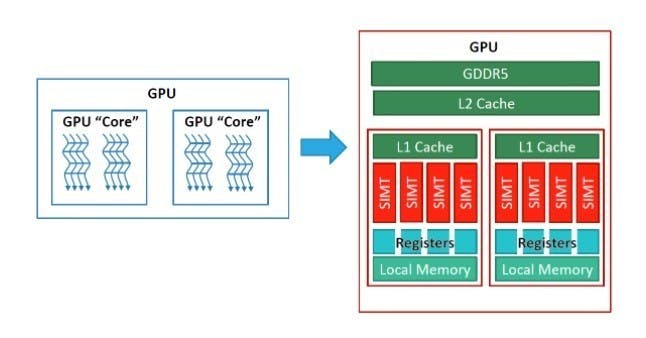
以NVIDIA的CUDA為例,代表畫面上一塊小方格、最多由32執行緒組成的「Warp」,是其GPU的基本運算單位,同一個Warp內的執行緒,共用同一個程式計數器 (Program Counter),執行相同的程式碼,但處理不同的資料。此外,如一個Warp因某些因素被迫停滯 (如等待記憶體存取),就會切換執行另一個Warp,確保GPU的執行單元被塞好塞滿。
而排山倒海的執行緒浪潮用以掩蓋運算延遲這件事就更不用提了,G80的Streaming Processor (SP) 的最低運算延遲是4 Cycle,意謂著8個SP要被塞32執行緒的Warp才有可能餵飽,一切都是套招套好的。
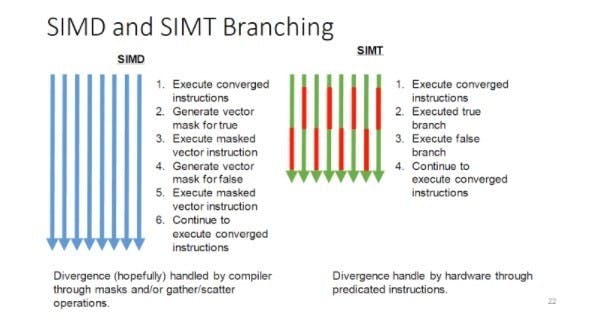
假使硬塞一沱執行緒給傳統「一個蘿蔔一個坑」的SIMD執行單元,慘劇就發生了:很容易發生執行單元空轉的狀態,還不如整個打散,採取類似MIMD的純量執行單元結構。講的更精確一點,SIMT寄望程式開發模型卻維持現有的簡單形式,讓SIMD享有接近MIMD的自由度,企圖兼具兩者的優點。
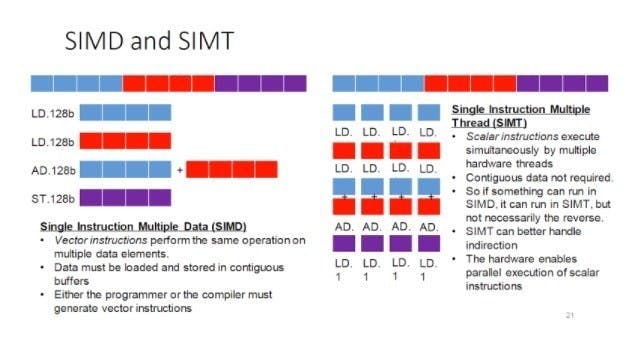
但要如何控制龐大執行緒的運行,特別是當進行條件判斷,決定執行哪些程式碼,「鎖存 (Lock Step)」哪些不予執行,這時候以前曾經在分析Apple自家處理器為何如此強大中提及的「引述碼 (Predication)」就派上用場了。
單一執行緒邏輯上可分成三個部份:引述碼、指令、暫存器編號,引述碼先跟執行單元演算器輸出的條件碼 (Condition Code) 進行比對,判定是否執行後繼的指令,與存取指定的暫存器,這精神上與向量電腦用以指定有效運算欄位的遮罩暫存器,頗有異曲同工之妙。
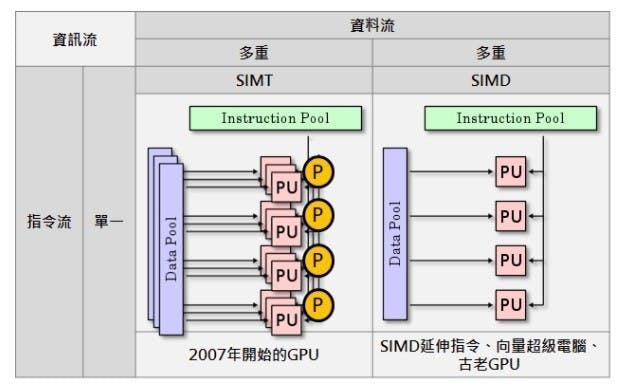
也因此,用以下這段話總結近代GPU,也許會比較貼切:GPU是由數個兼備SIMD簡易性與MIMD高彈性的「單指令多執行緒 (SIMT)」核心,所組成的單晶片多處理器,利於密集處理大量先天具有高平行度且高度同質性的運算工作。

")
")
")
")














