
各位站在時代浪頭的科科們,應該多少會注意到一件事:每當談到「巨大的晶片」時,眾人幾乎第一時間都會想到顯卡上面那顆大大的GPU,彷彿「君子不重則不威」。但你有沒有想過,為何GPU會持之以恆的「一眠大一寸」,在售價相近的前提下,都會比CPU「肥」上那麼多?
在這之前,請各位科科回想一下「GPU究竟是什麼」,我們再跳上時光機,回到1990年代末期那「還沒有GPU」的古老年代。
淺談GPU到底是什麼(中):兼具SIMD與MIMD優點的SIMT
如果納入不支援硬體幾何轉換 (Geometry) 功能的「前GPU」,繪圖晶片的肥大化,大致上可分為幾個階段。
前GPU時期:1990年代末期的多晶片架構
最具 (也是唯一) 代表性的就是當時的霸主3dfx了,初代的Voodoo加速卡 (SST1) 由兩顆處理器所構成,一顆Frame Buffer處理器 (FBI) 和一顆材質映射單元 (TMU),個別面積135 mm²,都各自有獨立的顯示記憶體。Voodoo2 (SST2) 則進一步變成一顆FBI搭兩顆TMU的巨大組態 (三顆都是119 mm²),但唯一的共同點就是「沒有2D顯示能力,所以請搭配一張標準的顯示卡」,而大學時代的筆者也就大手筆的用2D王者Matrox和3dfx Voodoo「送作堆」。
硬科技:光華電腦DIY回憶錄之Matrox顯示卡那短暫而美好的回憶
硬科技:光華電腦DIY回憶錄之3dfx沒落與NVIDIA崛起
除了過渡性強烈的Banshee (137 mm²,具備2D顯示功能,但是TMU只剩下一個),3dfx一直很堅持多晶片路線,還發展了雙顯卡的SLI模式,無可避免的堆高了成本,也難以攻入主流市場。反觀NVIDIA從初代的STG-2000 (NV1晶片) 一路到Riva TNT2 (NV5晶片),都是晶粒面積只有90 mm²的單晶片方案,這也註定NVIDIA終究將從3dfx手上搶來消費性3D顯卡的霸權。

在這裡同場加映後來被AMD併購的ATi,其Rage 128 (89 mm²) 在當時雖然效能不如NVIDIA RivaTNT和Riva TNT2,但卻是公認的放影片極品。ATi能夠與NVIDIA分庭抗禮,也就是GPU時代初期的往事了。
GPU發展初期 (1999年-2006年):著色器 (Shader Model) 讓GPU開始具有可程式化能力
GPU (Graphic Processing Unit) 一詞起源於NVIDIA發表於1999年8月31日的GeForce 256 (139 mm²,NV10晶片,Celsius微架構),NVIDIA對其定義為「整合3D轉換 (Transform)、打光 (Lighting)、三角設定 (Triangle Setup)/裁切 (Clipping) 與成像引擎 (Rendering Engine),每秒能處理至少1千萬個多邊形的單晶片處理器」,完全為自己量身訂做。
這時公司營運已陷入困境的3dfx依舊死性不改 (筆者猜想他們只想死守高獲利的高階產品),其末代產品仍採取多晶片架構,由渲染器Rampage (131 mm²) 和幾何處理引擎Sage (大約100 mm²) 所組成。其設定的競爭對手是同樣支援微軟DirectX 8.0 (Shader Model 1.0) 的NVIDIAa GeForce 3 (128 mm²,NV20晶片,Kelvin微架構),光看成本就知道凶多吉少。在2018年底,也是3dfx宣佈開發Rampage的二十年後,”The Legacy of 3dfx”一書的作者Oscar Barea,測試其手上的Rampage顯示卡工程樣品,證實其效能對上規格更加落伍的GeForce 256也絲毫佔不到任何便宜。
隨著3dfx破產被NVIDIA併購,我們也無緣見識到這場終極對決,只剩下3dfx的「技術遺產」投胎轉世到NVIDIA某些產品的鄉野傳聞。
ATi的Radeon 9700 Pro (215 mm²,R300晶片,Rage 8微架構) 擊潰NVIDIA GeForce FX 5800 Ultra (199 mm²,NV30晶片,Rankine微架構) 則奠定了ATi成為GPU巨強與NVIDIA最強競爭者的基礎。在2006年之前,GPU雙雄的旗艦晶片穩定的增肥到接近300 mm²的等級。
但更大的衝擊就要來臨了:一個是AMD在2006年的夏天,以54億美元的價碼,買下了ATi,配合其融合CPU與GPU「Fusion大戰略」,GPU發展策略開始偏向「運算」,而非「遊戲」;另一個,則是GPGPU時代的到來。
GPGPU開創期 (2006年-2009年):微軟DirectX 10 (DirectCompute 4.x) 的統一著色器架構 (Unified Shader)
2006年11月8日的NVIDIA GeForce GTX8800 (484 mm²,G80晶片,Tesla微架構) 和CUDA (Compute Unified Device Architecture) 的登場,替GPU通用化運算邁出了歷史性的一大步,也讓高階GPU的「體態」再度「天元突破」,再也無法回頭。

但在支援DirectX 10的進度落後NVIDIA整整半年的AMD,其史上首次支援64位元雙倍浮點精確度的Radeon HD 2900 (420 mm²,R600晶片,初代VLIW5的TeraScale微架構) 之後,卻從此跟NVIDIA分道揚鑣,轉向「兩顆小晶片打你一顆大晶片」的路線。
值得一提的是,早在1999年10月1日,ATi就推出兩顆Rage 128 Pro的Rage Fury MAXX,挑戰即將在10月11日正式上市的「歷史上首款GPU」NVIDIA GeForce 256,也理所當然的,完全沒有成功,如同嘗試藉由數顆缺乏硬體T&L的VSA-100、試圖抗衡NVIDIA GPU的3dfx。

首度支援OpenCL的R700家族,其中的Radeon HD 4800 (256 mm²,RV770晶片,初代VLIW5的TeraScale微架構) 不僅率先對應GDDR5記憶體,同時創下單晶片32位元單浮點精確度理論效能達到1TFlops里程碑,對手則是稍早的NVIDIA GeForce GTX 280 (576 mm²,GT200晶片,Tesla 2.0微架構),因這次AMD Radeon HD 4800 x2具備價格與效能的雙重優勢,在市場上獲取了相當的戰果。
不過彷彿AMD在CPU市場仍舊吃著K8的老本,在GPU戰場,備多力分的AMD,也快要用完所剩無幾的好運了。
硬科技:做為AMD全盛時期象徵的Opteron處理器:全盛期(2003-2007)
硬科技:做為AMD全盛時期象徵的Opteron處理器:逆轉期(2007-2010)
硬科技:做為AMD全盛時期象徵的Opteron處理器:崩潰期(2010-2017)
GPGPU熟成期 (2009年-2010年):微軟DirectX 11 (DirectCompute 5.x) 與IEEE 754-2008浮點運算精確度

當GPGPU走到這一步,才算擁有足以在高效能浮點運算取代CPU的資格。大概是因為NVIDIA GeForce GTX 480 (529 mm²,GF100晶片,Fermi微架構) 在台積電40nm製程上遭遇重大困難,這一次反倒是AMD Radeon HD 5870 (334 mm²,Cypress XT晶片,TeraScale 2微架構) 享有半年的領先。
IEEE 754-2008還制定了浮點乘積和 (FMA) 的精度標準,也就是「(a + b) x c = d」這類GPU最常碰到的運算類型。
當Fermi微架構的「完全體」GeForce GTX 580 (520 mm²,GF110晶片,Fermi 2.0微架構) 總算上陣後的兩個月,AMD Radeon HD 6970 (389 mm²,Cayman XT晶片,TeraScale 3微架構) 引進第三代TeraScale微架構,原先「四個簡單的向量運算單元 (4D) 加上一個複雜的特殊運算單元 (T Unit)」的VLIW5,改造為「四個可處理所有工作的運算單元 (4D T Unit)」的VLIW4,大幅改善指令排程與執行單元的效率,預先準備真正邁向GPGPU的GCN (Graphic Core Next) 微架構。
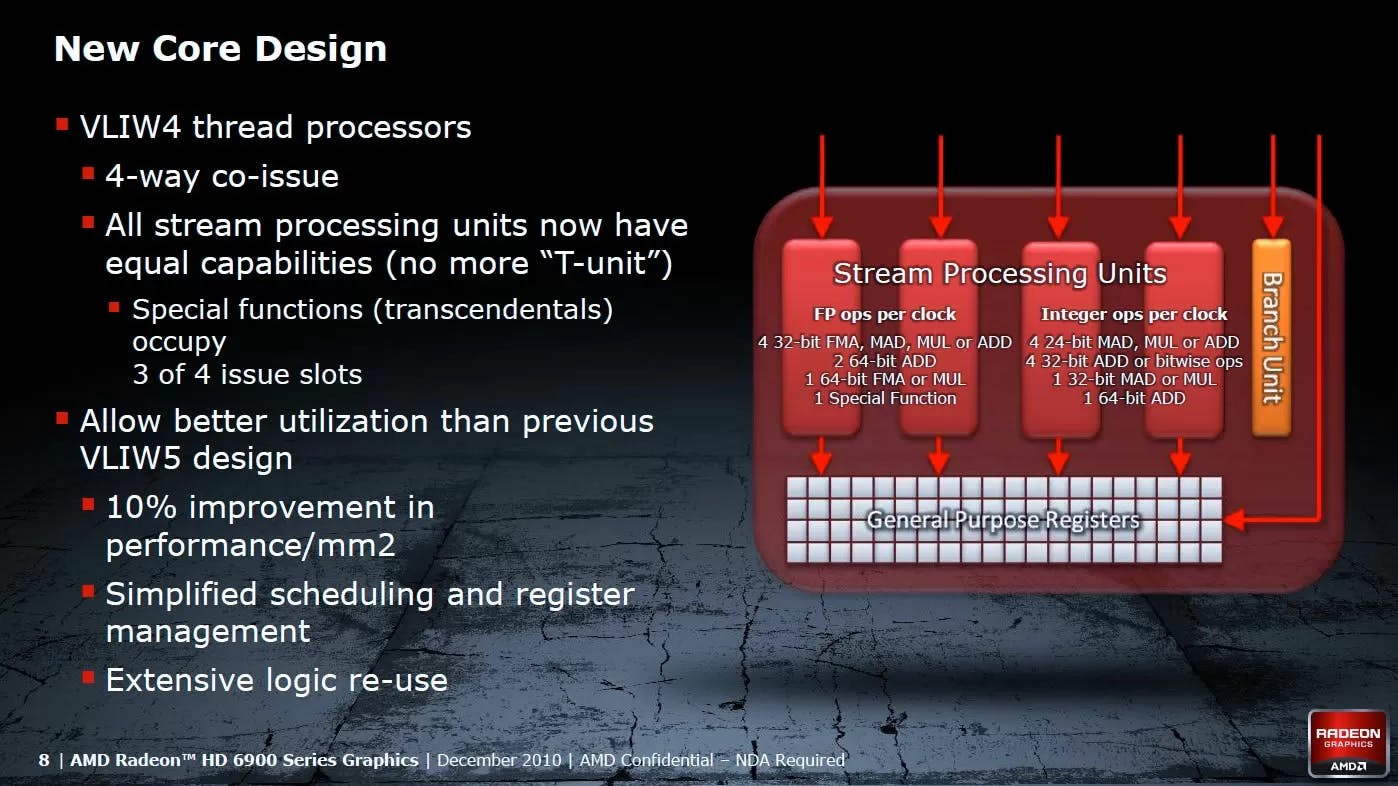
只不過,當NVIDIA開始有那個餘力去「分而治之」遊戲和運算,不再像併購ATi後的AMD一樣,眼睛只緊緊的盯牢著GPGPU (事實上,一直不乏「AMD的GPU擺明為了運算而生,怎麼看都不太像為了遊戲的微架構」這樣的說法,日後AMD也以實際的行動證明其所言不虛),因兼顧CPU和GPU戰線而備多力分的AMD,就要開始倒大楣了。
GPGPU實用期 (2010年-2016年):AMD的崩潰與漫長的28nm製程牙膏期
NVIDIA在2012年3月22日發表的GeForce GTX 680 (294 mm²,GK104晶片,Kepler微架構) 上演了「NVIDIA中駟打爆AMD上駟Radeon HD 7970 (352 mm²,Tahiti XT晶片,初代GCN微架構)」的脫線劇場,AMD就此一蹶不振,不但至今都尚未回復元氣,更在2015年的獨顯市場,市占率跌落到「18趴」的歷史新低。
從2012年初到2016年中旬,NVIDIA和AMD都死守台積電28nm製程好幾年 (這紀錄日後才被Intel的14nm牙膏打破),要在進步極度有限的製程中,擠出更多的效能,唯有完全分立「遊戲」和「運算」的微架構。
回顧過去,其實NVIDIA只做對了兩件事:
-
放棄G80 (Tesla) 以來,有點東施效顰CPU的超高時脈Shader,而轉向激增Shader數量。「中階」的GK104的Shader時脈只有前代頂規Fermi的三分之二 (1.5GHz→1GHz),但數量卻變成「三倍 (512→1536)」,直接倍增理論效能。從這裡可以多少看出高時脈設計對電晶體密度的負面影響。
-
切開遊戲和運算的產品線,徹底「放生」前者的雙倍浮點精確度效能,反正遊戲也根本用不到,甚至還可打造針對單一用途的微架構,例如Maxwell就完全不顧運算需求,而Volta則是連消費性產品型號都沒有。
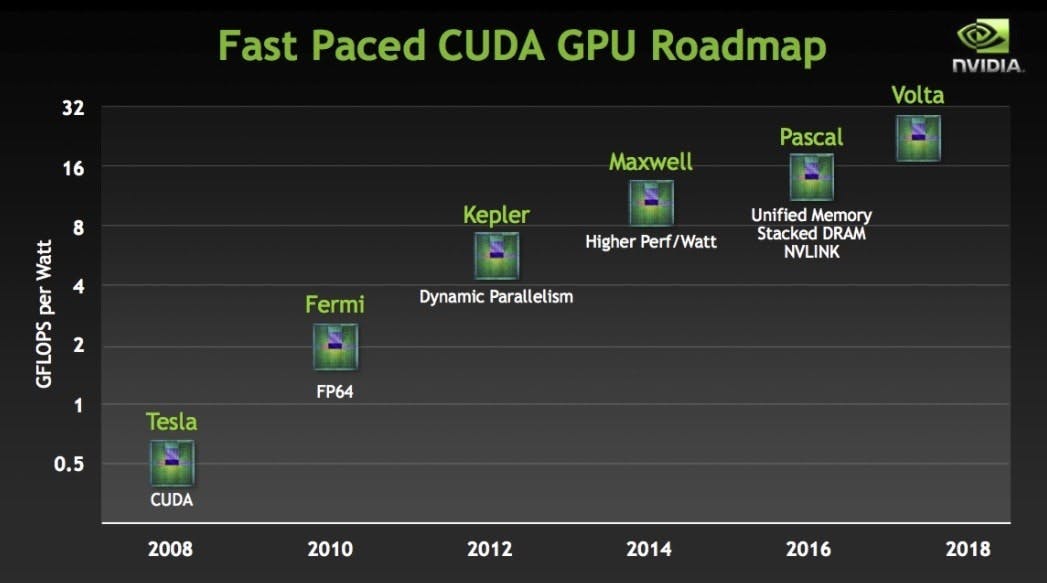
對AMD更不利的是,同時對Intel和NVIDIA兩面作戰,也就意味著缺乏足夠的資源去採取「雙軌共構」的產品發展策略,前前後後五個世代的GCN微架構,前面三個28nm製程者,完全是一路被NVIDIA活活打個半死的肉靶,到了第四代的Radeon RX 580 (232 mm²,Polaris 20晶片,GCN 4.0微架構) 才略有起色。即使GCN看似運算最佳化,但NVIDIA日漸成熟的CUDA生態系統和強勢的高階運算用產品線,卻也讓AMD絲毫佔不了任何便宜。
讓我們將焦點回到GPU的「體型」,製程微縮的停滯不前,也無可避免的催生更巨大的GPU,例如:
- NVIDIA GeForce GTX 780 (561 mm²,GK110晶片,Kepler微架構)
- NVIDIA Tesla K80 (561 mm²,GK110晶片,Kepler 2.0微架構)
- NVIDIA GeForce GTX Titan X (601 mm²,GM200晶片,Maxwell 2.0微架構)
- AMD Radeon R9 Fury X (596 mm²,Fiji XT晶片,GCN 3.0微架構)
但當GPU雙雄終於在2016年擺脫28nm製程的束縛,是否意味著高階GPU將有瘦身成功的可能?才怪,科科們難道不知道從事越「燒腦」的工作會更容易變肥的大道理嗎?
邁向人工智慧 (2016年至今):各式各樣的低精度資料格式與AMD發動的反擊
硬科技:一窺NVIDIA「真正人工智慧」Volta的執行單元細節
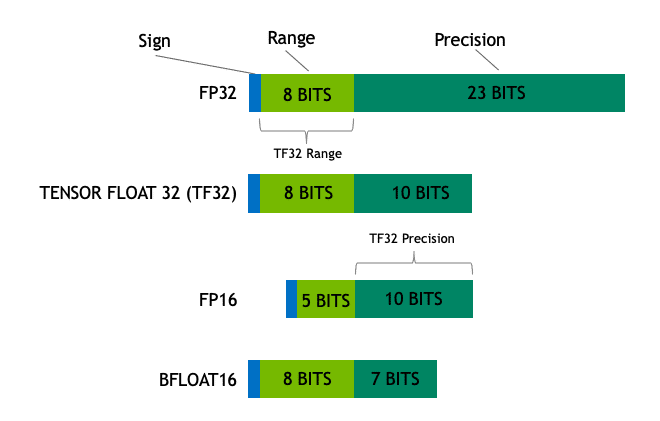
工人智慧... 呃,人工智慧早已深入我們的生活,無論是「推論」還是「學習」,看在減少資料容量和加快運算速度的份上,都不可避免的碰到一大堆奇怪的低精度資料格式,像INT8短整數、FP16短浮點、Google創造的BF16 (Bfloat16) 和NVIDIA發明的TF32 (TensorFlow32) 等,更衍生出專門的張量 (Tensor) 運算單元。
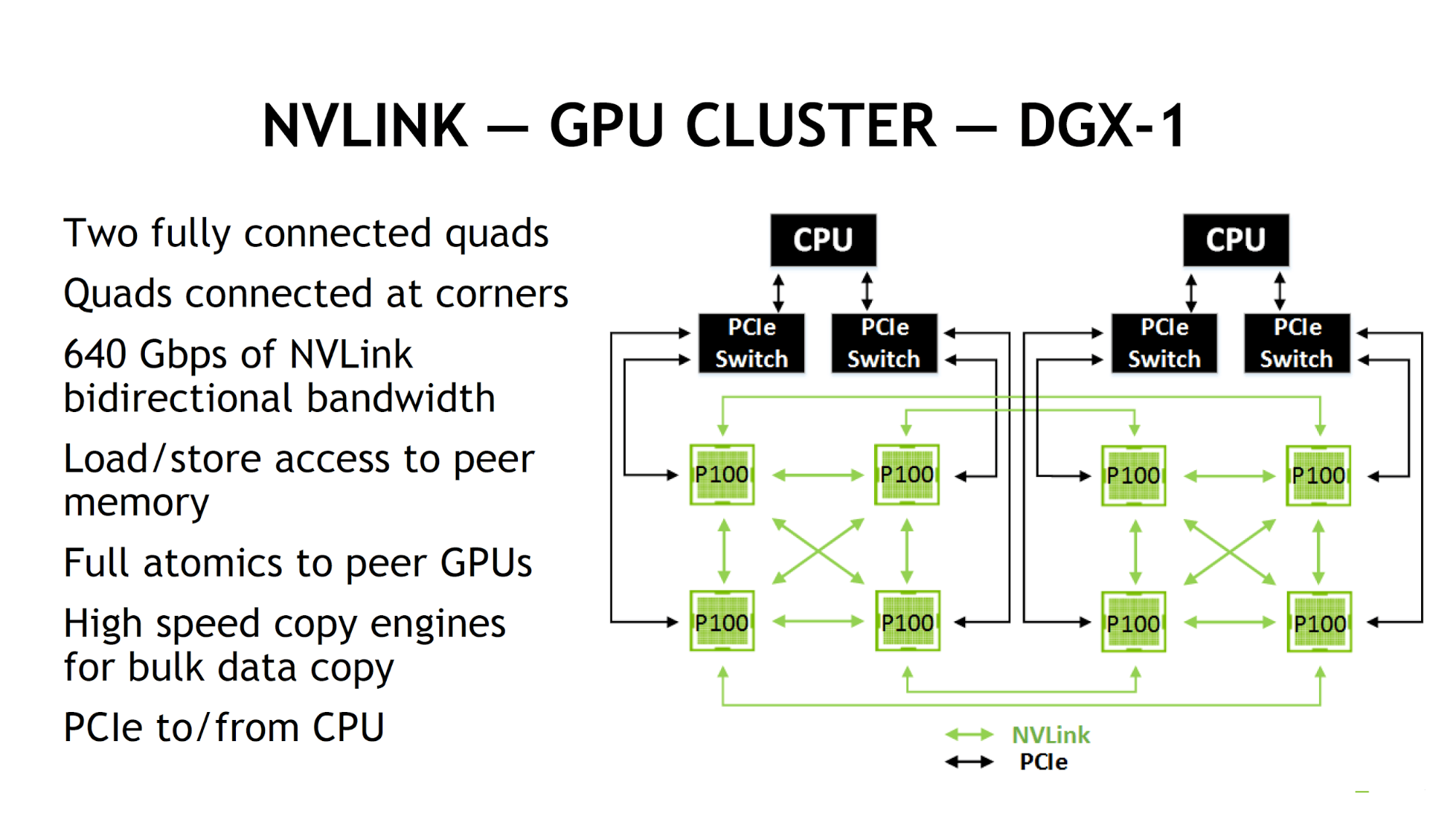
在GPU雙雄擺脫28nm泥沼的2016年,台積電16nm製程或三星14nm製程的NVIDIA Pascal微架構帶來了眾多革新,例如配置獨立的64位元雙倍精確度浮點運算單元、支援8位元短整數 (內積向量指令) 與16位元短浮點、導入HBM2記憶體和用來連接IBM Power8處理器的NVLink (號稱PCI Express 3.0的5至12倍效能)、以及追加統一CPU和GPU的記憶體定址空間並提供需求分頁 (Demand Page) 的Unified Virtual Memory,也順理成章的推出初代DGX-1深度學習系統。
也因此,NVIDIA Tesla P100 (610 mm²,GP100晶片,Pascal微架構) 並沒有因為新製程而比前代小,後繼純運算用的Tesla V100 (815 mm²,GV100晶片,Volta微架構) 更是突破天際到超過800 mm²的歷史新高,就筆者印象所及,論高階CPU,只有Fujitsu SPARC64 XII (795 mm²) 才能勉強比肩,像Intel IBM Oracle的伺服器晶片,別說抵達800 mm²大關了,連超過700 mm²都很困難。
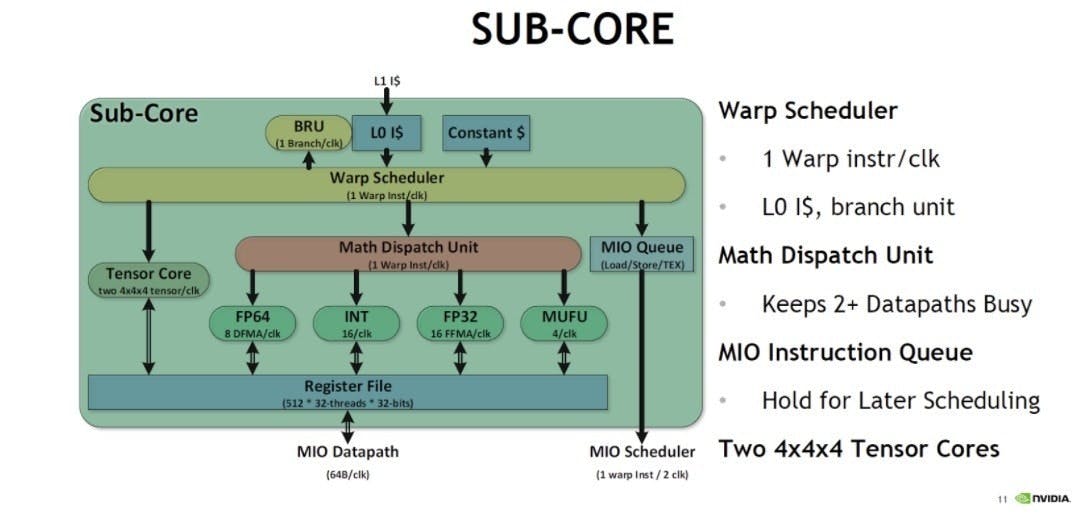
當NVIDIA Volta微架構的執行單元結構映入各位科科的眼簾時,各位科科也不難想見台積電12nm製程的GV100會如此的巨大,包含「五種」截然不同的獨立運算功能單元,一個次核心 (Sub-Core) 就有16個32位元浮點 (FP32,CUDA Core的同義詞)、4個特殊運算 (MUFU)、8個64位元浮點 (FP64)、16個整數運算 (INT)、與2個為人工智慧而生的張量運算核心 (Tensor Core)。
那麼,從2017年開始慢慢爬出低谷的AMD,狀況又如何呢?第五代GCN微架構的Radeon RX Vega 64 (486 mm²,Vega 10晶片,GCN 5.0微架構) 相較之下就「遜色」多了,但在2020年財務分析師大會昭告天下「我們也要切開遊戲和運算的微架構」,有趣的事情就發生了。
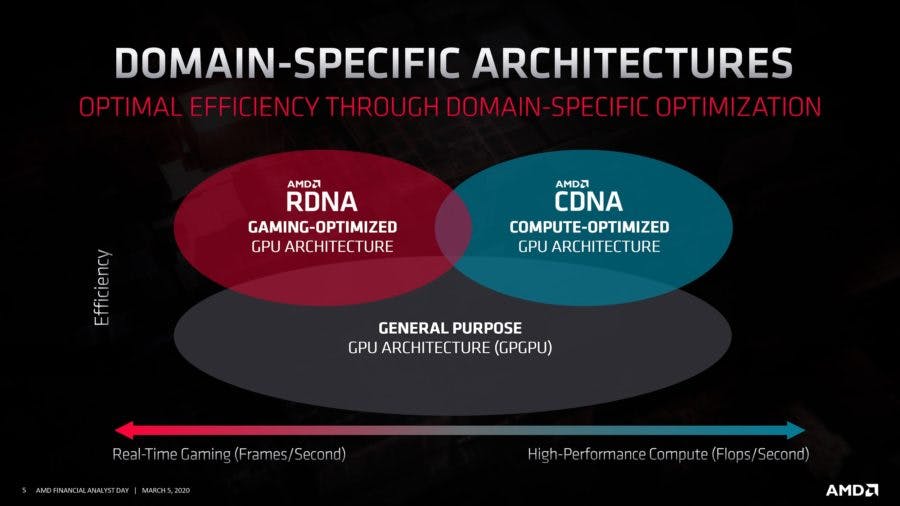
AMD先後在2019年2月發表Radeon VII (331 mm²,Vega 20晶片,GCN 5.1微架構,後來改稱CDNA 1.0)、7月發布Radeon RX 5700 (251 mm²,Navi 10晶片,Navi微架構,日後改名RDNA 1.0) 的舉動,就透露出不少蛛絲馬跡。
從2020年開始,運算用的GCN和遊戲用的Navi分別正名為CDNA和RDNA,AMD也在當年11月迎來史上最大的GPU:Radeon Instinct MI100 (750 mm²,Arcturus晶片,CDNA 1.0微架構)。也許當時AMD還是趕不上NVIDIA A100 (826 mm²,GA100晶片,Ampere微架構),但AMD在2021年11月8日的Radeon Instinct MI200系列 (面積不明,但肯定不會小,Aldebaran晶片,CDNA 2.0微架構),讓AMD一償「兩顆保證打死你一顆」的宿願,擁有帳面上的理論效能足以壓倒NVIDIA旗艦產品的高階運算GPU。
AMD在遊戲市場也略有起色,Radeon RX 6800系列 (520 mm²,Navi 21晶片,RDNA 2.0微架構) 也拉近了跟NVIDIA的距離,多達128MB的第三階快取 “Infinity Cache” 也成為AMD遊戲用GPU的「脂肪補充來源」。

行文至此,我們又要面對一個大哉問了:不只AMD,現在連企圖重返GPU市場的Intel,也透過先進封裝技術,創造出融合三種不同製程 (Intel 10nm、台積電7nm、台積電6nm) 的47顆晶片、電晶體總量超過1000億的Xe-HPC “Ponte Vecchio”,再考量到時下先進製程產能極度吃緊的世道,GPU還會繼續變肥嗎?

坊間不斷盛傳NVIDIA也將共襄盛舉,一起玩多晶片包水餃,我們也將很快看到最後的答案。但多晶片封裝能否改善顯示晶片的產能,紓解顯卡缺貨潮,才是對一般人最切身相關的課題吧。科科。

")

")
")
")
")
")
")
")









