
在今年超級電腦年度盛事 SC18 所公布的最新全球超級電腦榜單上,基於 NVIDIA GPU 加速的系統大放異彩,包括台灣杉 2 等多套新超級電腦系統在象徵性能的 Top500 與能耗效能的 Green 500 雙雙入榜,取得相當亮眼的表現,也驗證 NVIDIA 執行長表示透過 GPU 加速將持續推動產業摩爾定律的說法;而在 SC18 正式開始前一天, NVIDIA 執行長黃仁勳也進行主題演講,聚焦在 NVIDIA 如何透過軟硬體結合推動新一代超級電腦創新。

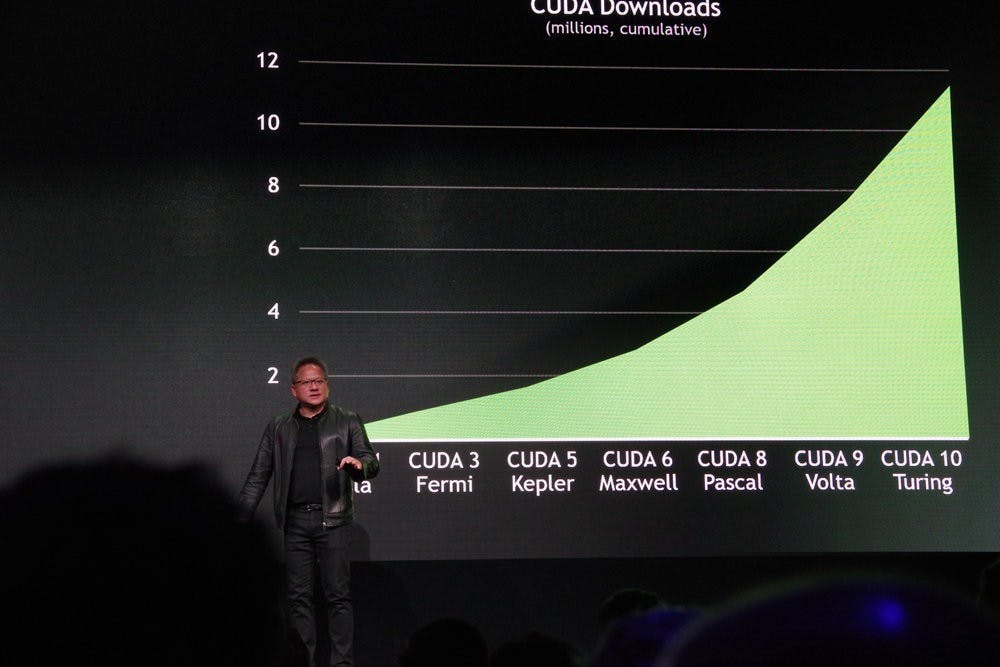
黃仁勳表示, NVIDIA 在 10 年前的 SC08 大會首度宣布基於 Tesla GPU 加速的個人超級電腦,而十年後的今日,基於 Tesla V100 GPU 的 Summit 成為全球最快的超級電腦,同時歐洲與日本最快的超級電腦也是基於 Tesla V100 ,並且在今年 Green 500 節能超級電腦榜單的前 25 名當中奪得 22 席,展現極高的能源效率,也證實 GPU 加速為超級電腦產業帶來全新的局面。
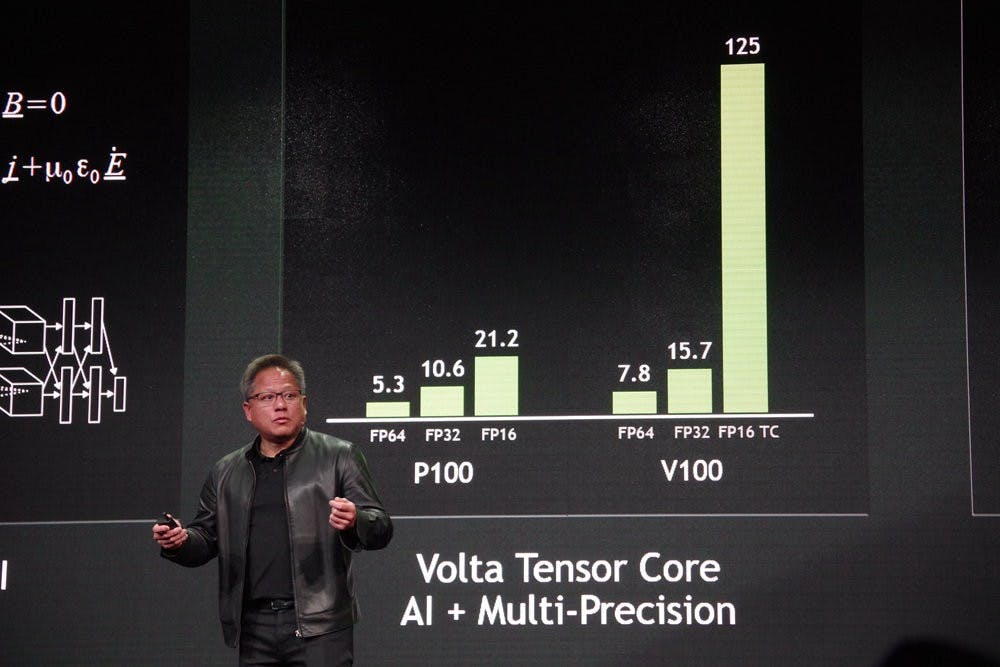
同時,為了面對越來越複雜的應用並用於更多的分析與研究,新一代的超級電腦也有全新的需求,為了提供不同類型的運算,混合精度運算與結合機械學習的超級電腦已成趨勢,尤其透過機器學習與深度學習的方式提升運算效率,更為超級電腦帶來更好的運算效率。
NGC 為 HPC 帶來容器化的下載後導入的易使用特色, RAPIDS 開源平台可為數據分析透過 GPU 大幅加速
然而,光是硬體並不足以讓 NVIDIA GPU 能在超級電腦領域有如此優異的表現,軟體與硬體的結合是相當重要的關鍵;透過 CUDA 持續不斷的發展, CUDA 在超級電腦業界與分析研究應用已廣泛的被支援,加上 NVIDIA 持續在硬體架構與 CUDA 軟體持續演進,促使每一版的 CUDA 都不斷使效能再攀升。
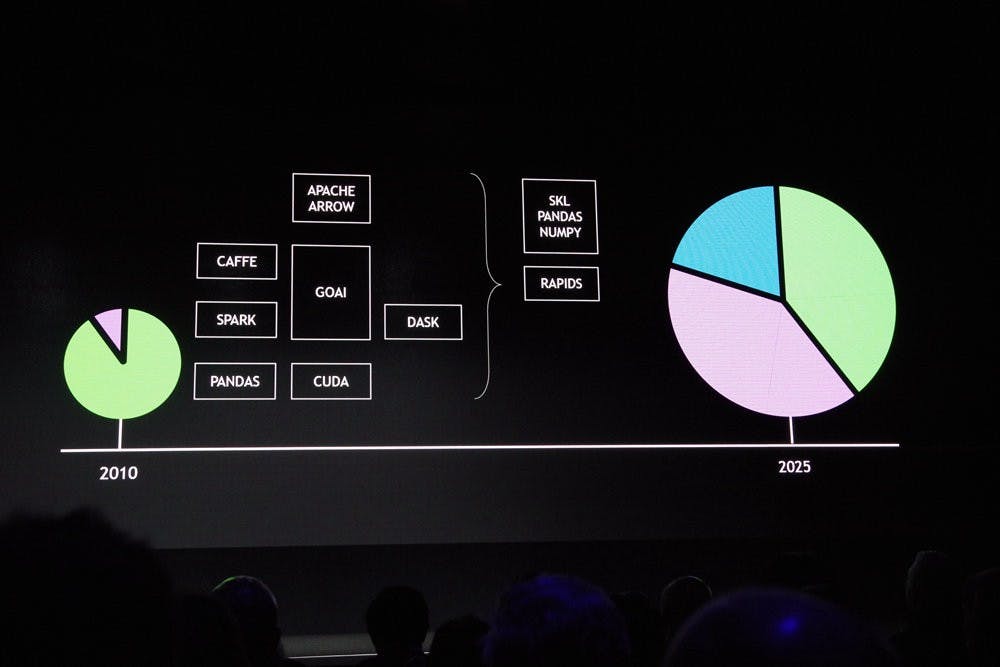
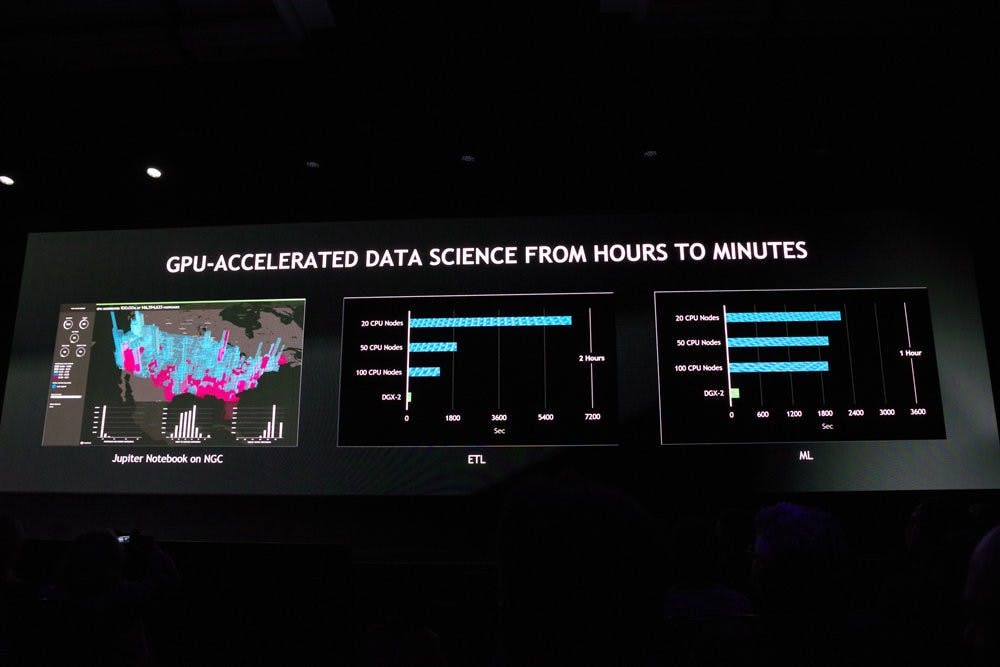
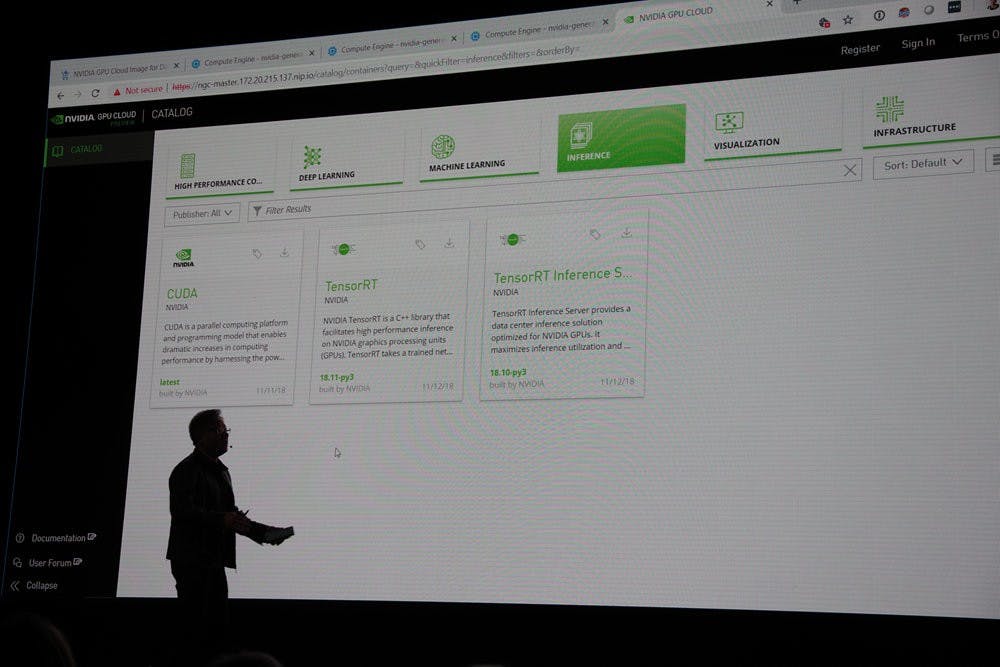
同時, NVDIA 也試圖讓開發者、研究人員更容易發揮與使用 GPU ,推出 NVIDIA GPU CLOUD 平台與 RAPIDS 開源加速平台兩項平台,分別提供深度學習 HPC 的容器下載與整合的數據分析資料庫工具,讓基於 GPU 的系統更容易安裝,以及能夠將數據分析更有效率的透過 GPU 執行。同時, NVIDIA 已經透過總部所架設的超級電腦系統進行測試,確保工具的性能、相容性與可靠性,使開發者不必擔心這些釋出的工具的品質,只需下載並使用。

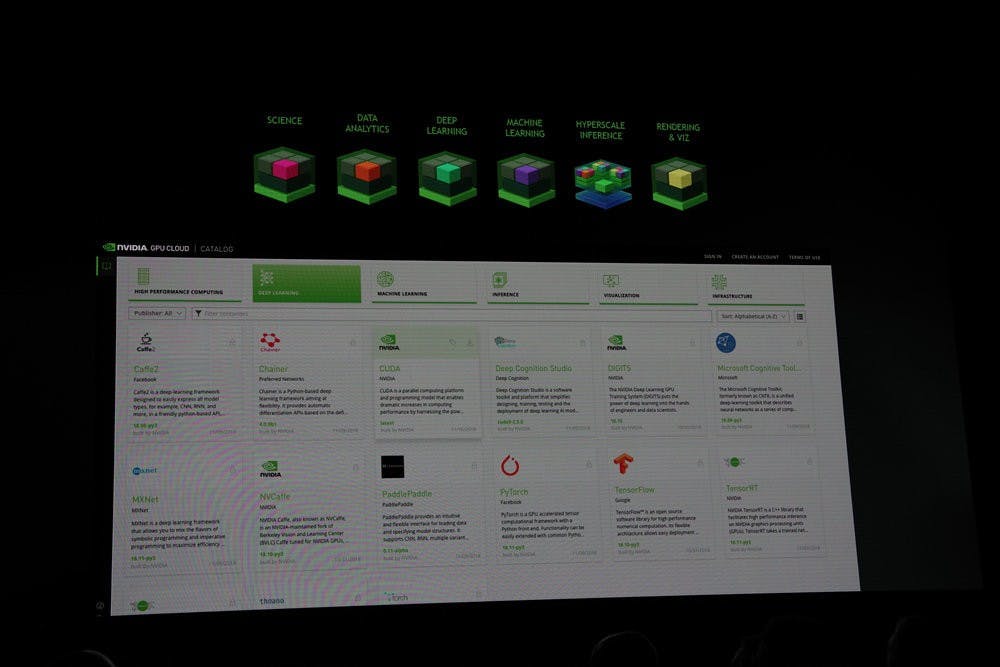
NVIDIA GPU CLOUD ( NGC )藉由提供不斷更新的各式深度學習與 HPC 應用容器,並以圖像化與分類的方式幫開發者預先過濾不同類型的容器,註冊的使用者可直接透過 NGC 下載,同時這些容器可在跨工作站、 Cluster 與雲平台等 NGC Ready 平台執行,並支援單加速器到大量加速器。

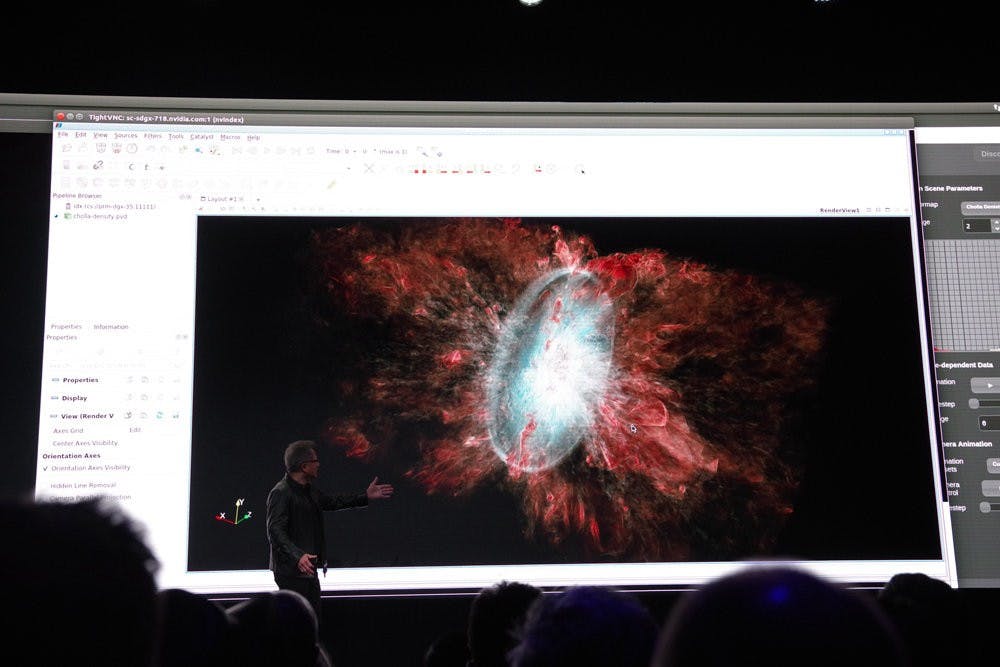

至於 RAPIDS 則是希望能解決過往複雜的超級電腦分析工具的平台,透過 In GPU Memory 的方式大幅加速這些數據分析的效率,其中針對資料分析、機器學習與影像分析個別提供 cuDF 、 cuML 與 cuGRAPH 等不同類型的工具,基於 Apache Arrow ,並有近似 pandas API 的特性,以開源方式拋磚引玉吸引開發者採用。在今天的活動, NVIDIA 更展示銀河的模擬,藉由 NGC 所下載與安裝的容器,搭配兩套 DGX2 將達 7TB 的數據透過 ParaView 模擬出約銀河系 1/5 規模的星系,並將結果轉化為 3D 的可視化影像。
藉 NVLink 與 NVSwitch 為超級電腦 Scale UP

提到超級電腦的性能提升,就會回歸到 Scale Up 單一系統縱向擴張與 Scale Out 系統規模橫向擴展兩者孰優孰劣,然而若以當前 CPU 的發展,乍看下要進行 Scale Up 似乎不太實際,然而黃仁勳表示,透過 GPU 加速的方式仍能為單一系統的效能帶來變革。
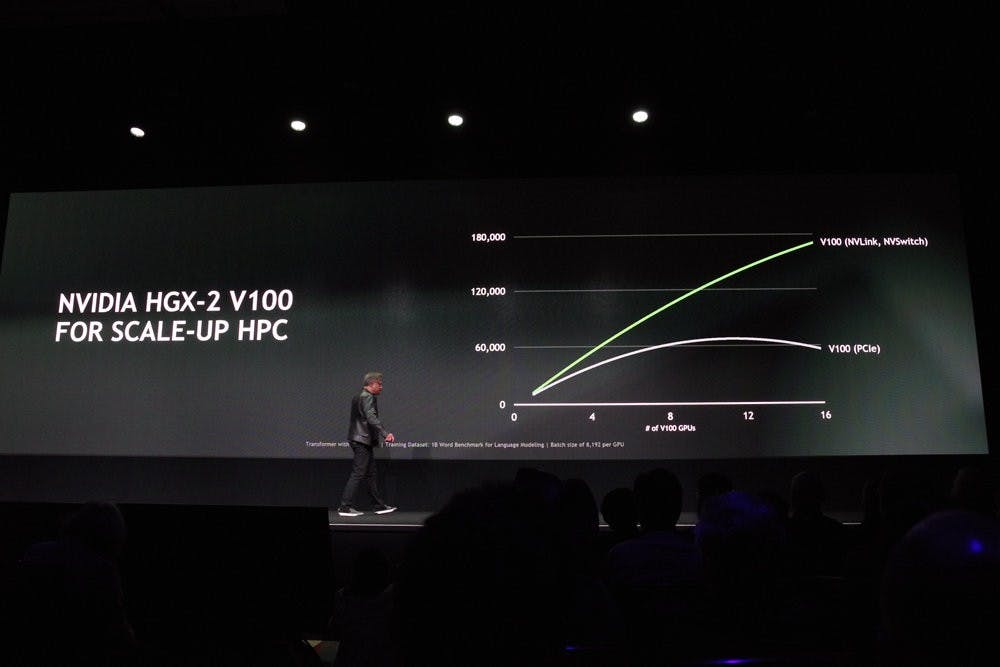
過往 GPU 加速在超級電腦的限制,取決在 GPU 上的記憶體雖較 CPU 的記憶體效能更高但容量卻不足,同時傳統的加速運算主控權握在 CPU 上,運算的結果需要反覆在 CPU 與 GPU 之間多次的傳輸,而多張 GPU 之間又須透過 CPU 控制,且以當前的 PCIe 介面亦不足以負擔多張 GPU 運算所需的效能,甚至在連接達 16 張 GPU 時,由於頻寬阻塞與管理問題,反而使性能下降。




有鑑於此, NVIDIA 在 Pascal 架構的 Tesla P100 導入 NVLink 技術,不僅提供比起 PCIe 更大的頻寬,亦可使 GPU 與 GPU 直接溝通,同時還可讓串聯在同一個 NVLink 上的最多 8 個 GPU 的記憶體共享,也解決一部分的問題。

而在採用 Tesla V100 的 DGX2 上, NVIDIA 進一步透過 NVSwitch 將兩組 NVLink 上共 16 個 GPU 構成一個更大型的 GPU ,不僅再度使 GPU 規模增加獲得更高的運算力,不會如過往多 GPU 連接時效能會有顯著折損的現象,當連接到 16 個 GPU 時的性能依舊呈現線性提升,同時並可更進一步使單一超級電腦上的 GPU 加速器有更大的記憶體容量。就結果來說,原本模擬阿爾卑斯山附近約一百萬平方公里範圍的一日天氣預測,約需要達 175 台 CPU 超級電腦的規模,現在僅須透過一台 DGX-2 以 1/6 的功耗,即可在 20 分鐘內達成,達到以一抵百的表現。
透過 Turing 圖靈架構的 Tesla T4 Cloud GPU 為超級電腦縱向 Scale UP 、橫向 Scale Out



黃仁勳也提出,除了單一系統的性能擴張以外,為了讓大規模的系統能夠獲得飛躍的效能提升,同步進行系統擴張與規模擴展是必行知道;其中的關鍵就是甫於日本 GTC 所發表、基於 Turing 圖靈架構的 Tesla T4 Cloud GPU 。 Turing 圖靈架構除了具備 CUDA Core 外,透過加入 Tensor Core AI 加速核心,藉具備包括多精度運算的 Tensor Core 大舉提升如機器學習與深度學習的性能,同時僅 75W 的 TDP 亦使 Tesla T4 的尺寸相當小巧。


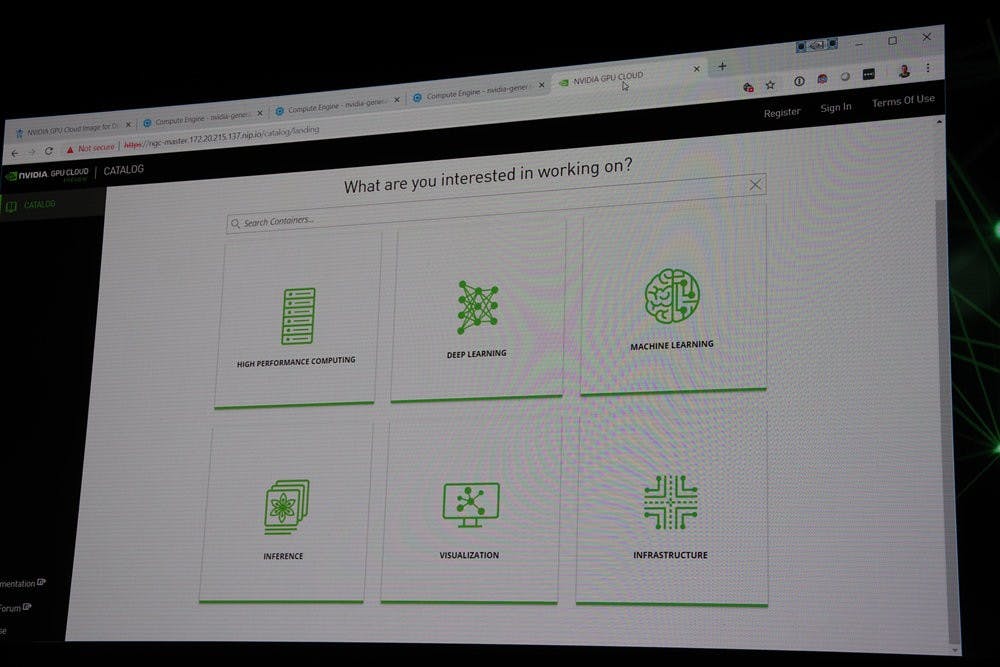
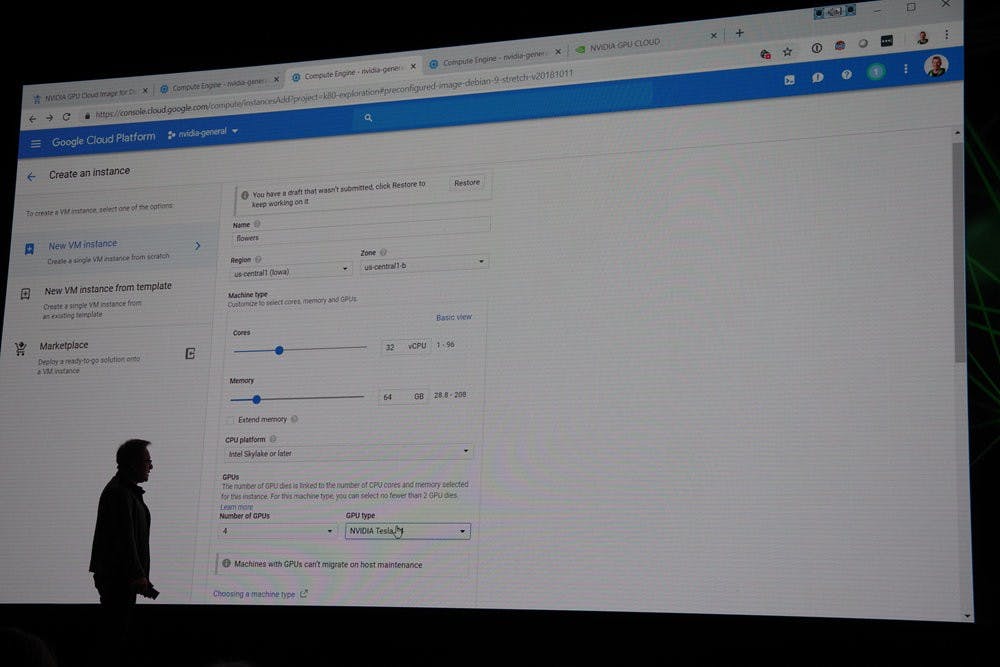


也因此, NVIDIA 與合作夥伴也將兩張 Tesla T4 配置在業界標準規範的 OPC 模組當中,使採用 OPC 模組化的機架式伺服器能夠一舉進行縱向擴張性能,同時搭配 NGC 與 RAPIDS ,使多個伺服器的 GPU 資源得以進行橫向擴展;在今天的主題演講,亦透過 RAPIDS 調配 Google Cloud 的 Tesla T4 GPU 進行花卉的種類分類的影像辨識,僅須透過複製一行指令,即可在原本僅支援單一系統、 4 張 GPU 變成可動用達 32 個 Tesla T4 GPU 使效率倍增,達到一秒辨識 5 萬張以上花朵圖片的性能。



















