
NVIDIA 在今年 GTC 大會宣布首款針對超級運算、 AI 與資料中心的 CPU 產品,以知名女性程式設計師 Grace Hopper 做為產品代號,並採用 Arm 的 Neoverse CPU 架構作為基礎,從表面來看, Grace 是 NVIDIA 首度跨足超高效能 CPU 領域,但從對 NVIDIA 整體布局而言, Grace 更是使 NVIDIA 實現理想加速運算的樞紐。
對於 NVIDIA 而言,基於 GPU 的異構加速運算是他們自消費娛樂、視覺影像邁向超級運算之路的關鍵,除了科學運算領域以外,在使用機械神經網路架構的機器學習成為 AI 主流後, NVIDIA 更進一步成為新世代加速運算的關鍵廠商,然而從系統的角度, GPU 終究在加速運算扮演資料運算,但仍需搭配 CPU 執行基本的系統,以及由 CPU 發號運算的命令。

另一項問題則是 GPU 的 VRAM 單位成本較 CPU 搭配的系統記憶體高,同時總體容量也較小, NVIDIA 雖試圖透過各種方式解決 GPU 記憶體容量大小的問題,例如以 NVLink 貫串多張 GPU ,使多張 GPU 化為一個大型 GPU ,但對比當前資料中心級 CPU 可動用的記憶體仍小了不少。
NVIDIA 從多年前就設法解決這些領域的問題,例如過往加速運算需要反覆在 CPU 與 GPU 之間重複發送運算需求、接收運算成果的輪迴,改以偵測到下一步仍可於 GPU 運算即可繼續在 GPU 執行,與當年發表 NVLink 技術希望能統合多個 CPU 、 GPU 的多向溝通與記憶體直接存取。
在這些技術當中,高速通道技術 NVLink 顯然是扮演相當重要的角色,因為以往 GPU 作為系統擴充卡的身分,需要透過 PCIe 通道與 CPU 連接,但由於相較 CPU 與系統 RAM 或是 GPU 與 VRAM 的通道速度低了許多,縱使能夠提供 CPU 、 GPU 、 RAM 與 VRAM 的資料共享,但卻呈現傳輸性能跟不上運算性能的情況, NVLink 的設計目的即是提供跨晶片的高速連接通道。

不過 NVLink 雖在架構可支援 CPU 與 GPU 的相互連接,然而 NVIDIA 至今找到的合作夥伴也僅有較冷門的 IBM Power ,雖然當時 Tesla P100 世代可搭配 IBM Power 8 處理器發揮強大的效能,但始終市場上仍由基於 x86 處理器以 PCIe 搭配 NVLink GPU 迴路板的系統作為主流大宗。
NVIDIA 會設法另闢新局,主要是 IBM Power 在超算系統的市佔與資源相對 x86 不理想,但握有 x86 架構的 AMD 與 Intel 又各自有自身的加速器產品,也不可能捨棄成見加入 NVIDIA NVLink 的支援行列,最終的選擇就是要設法另起爐灶。

從市場規模,生態資源來看, Arm 架構在超算領域雖仍為萌芽期,後勢卻看漲,除了富士通以 A64FX 的富岳系統奪得 TOP 500 榜首外,更包括 Arm 架構自智慧手機開始建構龐大的生態環境,加上 NVIDIA 藉由原本發展平板電腦、智慧手機轉型嵌入式超算的 Tegra 產品線一路到目前的 NVIDIA Drive 、 NVIDIA Jetson ,已經逐步有完整的加速運算條件與環境。
Arm 架構在智慧手機時代前主要是作為微控制器應用,但隨著智慧手機引領的行動運算需求, Arm 架構當前也能執行完整的作業系統,除了 Windows 10 on Arm 、蘋果的 MacOS on M1 以外, Linux 系統更早就具備在 Arm 架構執行的能力,同時 NVIDIA 推廣 Jetson 與各種嵌入式環境時,也逐步完成 Arm CPU 與 NVIDIA GPU 的環境,此外多家資料中心廠商如亞馬遜也開始採用自主 Arm 架構晶片提供服務,更不用說收購 Arm 以前就宣布基於 Arm 的超算系統與 NVIDIA GPU 的連接計畫。

若從發展歷程來看, NVIDIA 一路走到發展 Arm 自主架構超算處理器是不令人意外的局勢, NVIDIA 在 2008 年就已經與 Arm 合作推出第一代的 Tegra APX ,同時也採取消費、車載與嵌入式多領域共同發展的模式,不過隨著智慧手機與平板市場競爭激烈, NVIDIA 自 Tegra K1 開始即淡化消費級產品發展,積極投入車用與嵌入式應用,後續再轉型先進輔助駕駛與自動駕駛應用,此外除了使用 Arm 標準微架構外,中間亦有幾代 Tegra 使用自主設計的 Denver CPU 架構。
這次推出 NVIDIA Grace 的關鍵莫過於去年宣布將自 SoftBank 接手 Arm 一事,雖然這樁合併案變數極多,不過自近期 NVIDIA 的產品布局,收購 Arm 確實有助強化雙方的技術布局, NVIDIA 能夠更深入 Arm 指令集的技術,同時亦可藉由 Arm 推廣部分 NVIDIA 的開放 IP ,例如用於 Xavier 的 Xavier DLA 加速器,以及 GPU 加速技術 CUDA 、 AI 視覺強化技術 DLSS 等,而 Arm 最重要的是取得能夠持續發展的資金挹注,畢竟當前開發一項架構都是燒錢。

眼尖的讀者朋友應該有看到此次發表 NVIDIA Grace 的主視覺與以往發表各類晶片都不太相同, NVIDIA Grace 的主視覺是一張完整的單板(推測可能微 SXM 模組)而非晶片,同時可看到單板上面不僅只有一顆 CPU 晶片,還包括 DPU 、 LPDDR5X ECC 記憶體等,同時輔以使用 NVLibk 通道技術,完全為搭配 NVIDIA 下一代 GPU 超算平台而來。
簡單的說, Grace 不僅是單一顆 GPU ,而是包含 CPU 、 DPU 、記憶體等的完整模組,同時專為連接 NVIDIA GPU 所設計,從 NVLink 的特性以及先前 NVIDIA 執行長介紹以 NVLink 連接的 GPU 的方式,筆者認為 Grace 藉由 NVLink 搭配下一代 NVIDIA 超算級 GPU ,根本就是一顆超大型的 SoC 晶片。
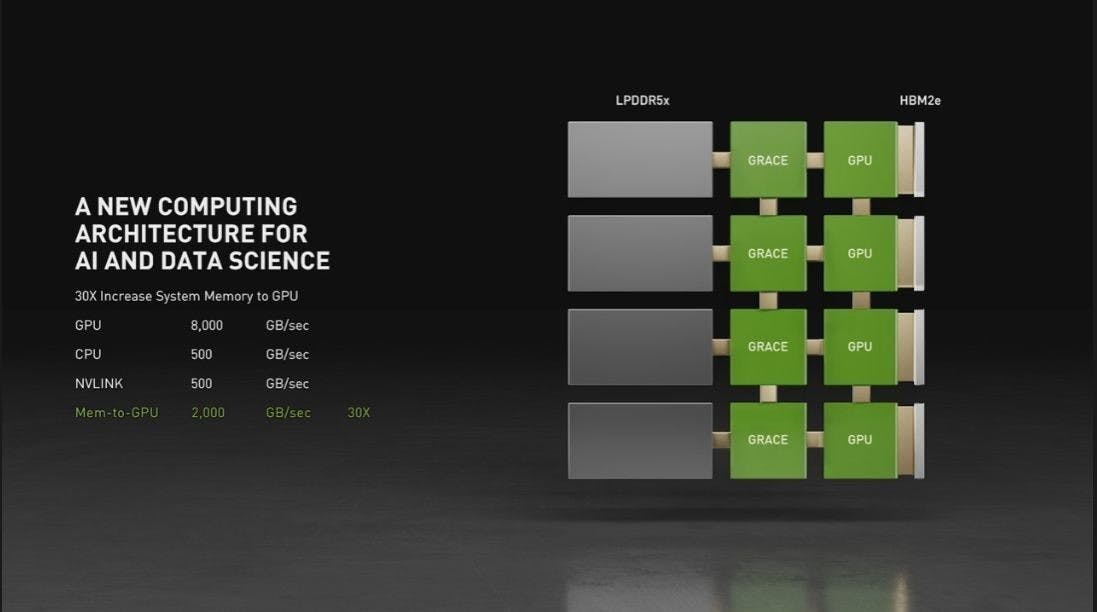
因為 NVLink 能夠提供 CPU 、 GPU 與記憶體之間充裕的 900Gbps 頻寬,同時又能構成 4 張 Grace 模組與 4 張次世代 GPU 的相互溝通與統一記憶體共享,整套 NVLink 迴路等同是超大型的高度整合晶片一般。同時藉由 NVLink 帶來的頻寬,結合 Grace 板載的高速 LPDDR5X ECC 記憶體,在此迴路當中將能實現把系統記憶體與 GPU 記憶體累加容量,同時又彼此可透過超高速相互讀取的特質,猶如當前智慧手機、遊戲機所採用的記憶體溝通模式。
此外, Grace 整合 DPU 的重要目的,也是透過在架構直接整合 DPU ,以 DPU 協助處理虛擬化與雲原生 AI 工作負載,使 CPU 、 GPU 更能專注在處理運算內容,進而使系統效率更為提升,同時又可利用在單一介面卡整合的方式,使 DPU 不需要連接在傳輸頻寬較低的外部介面卡,實現透過 NVLink 建構的單一大型 SoC 即可具備 NVIDA 加速運算三大核心的機能。
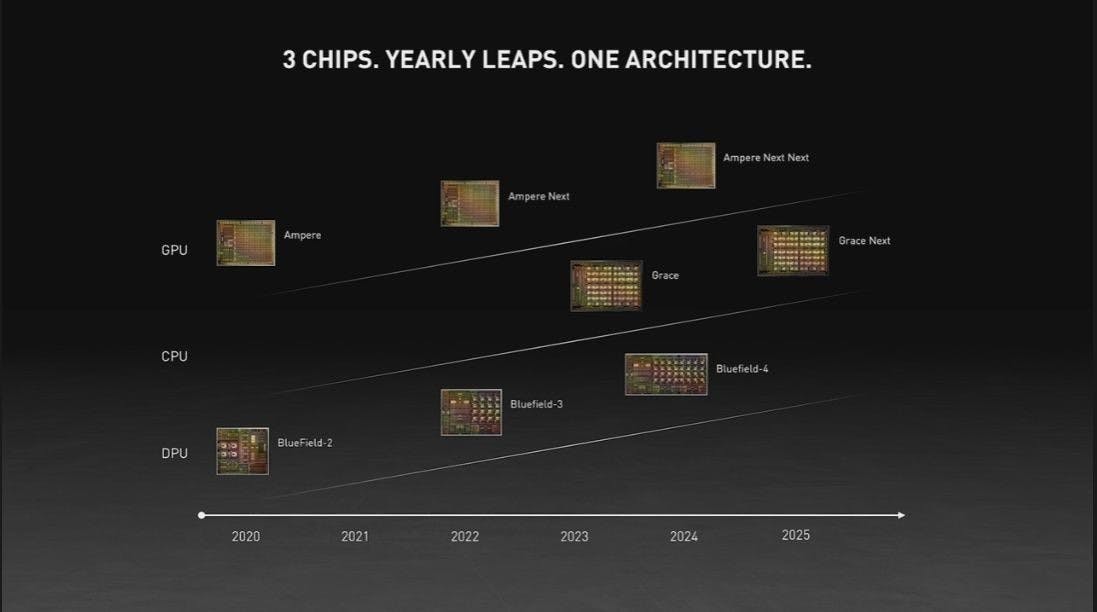
雖然 NVIDIA 是否能順利收購 Arm 還是未知數,不過筆者可肯定的說這項計畫不會重演當初 NVIDIA 進軍消費級 Arm 架構處理器煞羽而歸(其實嚴格來說當前反而靠任天堂還有所關聯)的結果,因為在 AMD 當前氣勢正旺、 Intel 除了收購 FPGA 廠商外也投入運算級 GPU 的開發,以往缺乏 CPU 的 NVIDIA 勢必需要自立自強,此次在 GTC 也率先公布 Arm CPU 的藍圖,至少 NVIDIA 在 Grace 推出前就已確立 2025 年推出 Grace 後繼產品的規劃, NVIDIA 攜手 Arm 與 x86 陣營抗衡的情況已成定局。



















