
NVIDIA 在今年 GTC 大會的重頭戲就是新一代的超算級 CPU 產品、代號" Hopper "的 NVIDIA H100 , NVIDIA H100 是作為基於 Ampere 架構的 NVIDIA A100 的後繼產品,採用台積電 4nm 製程,具備 800 億個電晶體,配有 80GB HBM3 記憶體,並具備革命性的 Transformer 引擎與第 4 代的 NVLink 架構,涵蓋自超算、人工智慧到數位孿生等領域。
NVIDIA H100 預計在今年第三季開始供貨,並由全球的雲服務供應商、系統商與 NVIDIA 提供系統與產品。目前包括阿里雲、 Amazon AWS 、百度人工智能雲、 Google Cloud 、微軟 Azure 、 Oricle Cloud 、騰訊雲等採用,並將提供雲端實例;至於系統製造商方面則包括 Atos 、 BOXX Technologies 、 Cisco 、 Dell Technologies 、富士通、技嘉、 H3C 、
HPE 慧與、浪潮、聯想、 Nettrix 和 Supermicro 等。
採用 HBM3 記憶體、外部頻寬達 5TB 、支援 PCIe Gen 5 的 NVIDIA H100



NVIDIA H100 建立在 NVIDIA GPU 運算的架構延續性基礎,並具備多項全新的技術特質,不僅使用台積電 4nm 製程製造,並借助 NVLink 技術達到近 5 TB 的外部連接傳輸速度,同時也支援 PCIe Gen 5 與頻寬達 3TB/s 的 HBM3 記憶體,強調 20 張 H100 GPU 的即可負荷全球網際網路的流量,使採用客戶能進行對即時數據導入高階推薦系統以及大型語言推論模型。

NVIDIA H100 也導入全新的 Transformer 引擎技術,因應目前 Transformer 模型為現今自然語言處理的首選標準模型, NVIDIA H100 藉由導入 Transformer 引擎使深度學習網路的執行速度相較 NVIDIA A100 提升 6 倍,同時也不因此耗損準確性。
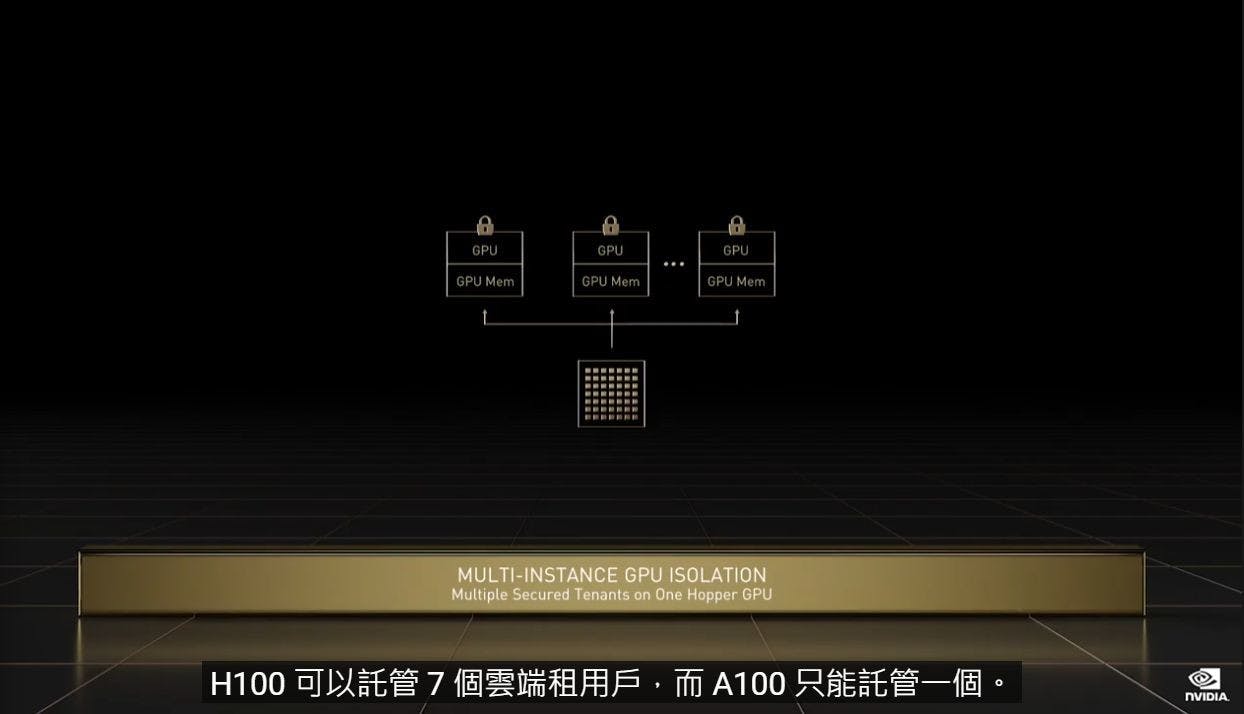

在上一世代的 NVIDIA A100 其中一項特色就是具備 MIG 多執行個體, MIG 能使 NVIDIA A100 隔離為 7 個執行個體,並在安全的環境中執行多項作業與運算; NVIDIA H100 的第二代 MIG 技術可在雲環境中進行跨 GPU 為每個 GPU 執行個體提供安全的多租戶配置,相較地一世代 MIG 擴展 7 倍,進一步使雲環境的安全環境多租戶應用提供更多的配置彈性。
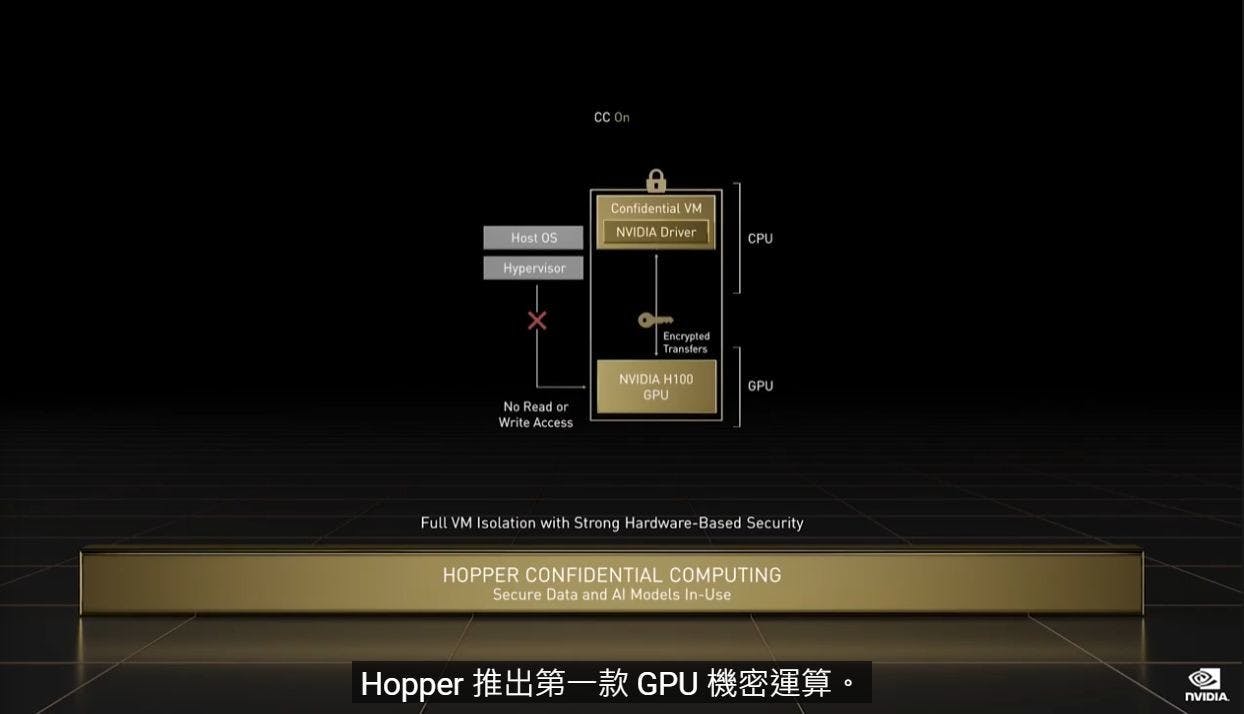
另外, NVIDIA H100 也針對安全性,率先在 GPU 導入機密運算技術,為全球首款具備機密運算的加速器產品,包括在進行 AI 人工智慧與數據處理為資料進行保護,尤其對醫療運算、金融服務等敏感性資料處理,或是由多個提供機密資料來源進行聯邦學習時,可借助機密運算進一步提升資料的安全防護能力。
同時, NVIDIA H100 還具備第 4 代 NVlink 技術,不僅頻寬達到 PCIe Gen 5 的 7 倍,使單一 NVLink 迴路的 8 個 GPU 以更快速的頻寬進行連接,借助全新的外部 NVLink 交換器 ( NVLink Switch )進行擴展,不僅可連接最多 256 個 NVIDIA H100 GPU ,相較 NVIDIA A100 所使用的 NVIDIA HDR Quantum InfiniBand 頻寬更高出 9 倍。
NVIDIA H100 支援全新的 DPX 指令, DPX 是全新的指令動態編程技術,可應用在包括線路最佳化與基因組學等廣泛的算法上,相較 CPU 在動態規劃執行速度提升 40 倍,且對比 NVIDIA A100 亦提升 7 倍性能,能夠應用在工廠自動化倉儲管理的自主機器人最佳路徑規畫的 Floyd-Warshall 演算法,以及用於 DNA 與蛋白質分類與摺疊的序列比對的 Smith-Waterman 演算法。
借助上述的創新技術, NVIDIA H100 不僅在純運算性能較 NVIDIA A100 大幅提升,同時也進一步擴大 AI 推論與訓練的領先優勢,例如在執行目前地表最強大的語言模型 Megatron 530B ,能較上一世代提高 30 倍的數據吞吐量,使 AI 對話的延遲縮減至近乎即時的次秒/ Sub-Second 等級,並使開發人員在進行訓練如 Mixture of Experts 達 3,950 億個參數的巨量模型時能提升 9 倍效率,將模型訓練時間自數周縮減至數天。
以 SXM 模組與 PCIe 單卡因應多種需求提供加速卡到加速系統等規格


NVIDIA H100 也將因應不同的應用需求提供多種產品型態,以 SXM 與 PCIe 兩種基礎單卡規格擴充,其中在系統級產品包括 NVIDIA DGX H100 以及基於 DGX H100 的 DGX H100 SuperPOD , DGX H100 以 8 個 NVIDIA H100 GPU 構成,借助 NVSwitch 技術, 8 個 GPU 以高出前一代 1.5 倍頻寬的 900GB/s 頻寬第 4 代 NVLink 連接,以全新 FP8 精度具備高達 32 petaflops 的 AI 性能。

而 DGX H100 SuperPOD 則是利用外部的 NVLink 交換器進行連接,單一交換機最多可連接 32 個 DGX H100 節點; NVIDIA 也將透過 DGX H100 SuperPOD 建構新一代自主 AI 超算系統,命名為 EOS , NVIDIA EOS 系統將連接達 576 個 DGX H100 節點,將是屆時全球性能最高的 AI 系統。

NVIDIA H100 亦將提供多種單卡型態,除了用以 4 卡與 8 卡 NVLink 迴圈連接的 H100 SXM ,亦針對主流伺服器提供基於 PCIe 5 的 H100 PCIe , H100 PCIe 仍可進行雙卡連接提升性能與總記憶體容量。此外針對如資料中心與 5G 訊號處理等 I/O 密集應用, NVIDIA 還將提供 H100 CNX 融合加速卡,將 NVIDIA H100 與 ConnectX-7 SmartNIC 結合,借助 CinnectX-7 與 NVIDIA H100 的直接結合進行資料處理加速。
當然代號 Hopper 的 NVIDIA H100 的殺手鐧不僅於此, NVIDIA H100 亦將成為預計 2023 年第一季推出的 NVIDIA 超算級 Arm 架構 CPU " Grace "的最佳組合, NVIDIA H100 與 Grace 能夠借助全新的晶片對晶片連接技術 NVLink-C2C 進行高速通訊,構成超高性能的" Grace Hopper " Superchip 模組單晶片,詳細內容會在另一篇進行介紹。



















