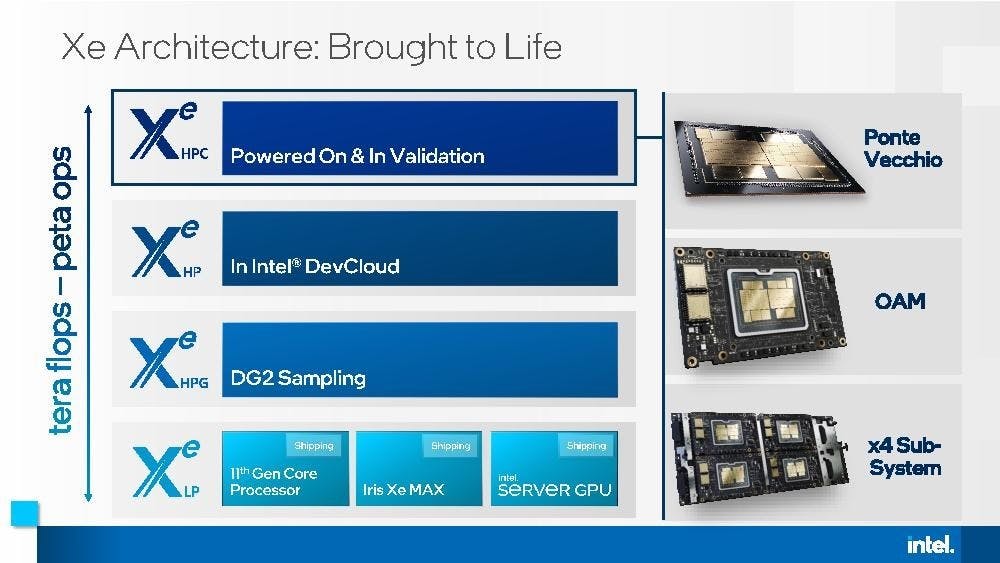
Intel 針對 HPC 與 AI 高效能運算推出 Max 系列 Xeon GPU 與資料中心 GPU , Sapphire Rapids HBM 與 Ponte Vecchio 為首世代產品線
Intel 向來相當擅長產品與技術品牌經營,畢竟如膾炙人口的 Centrino 、 i3 、 i5 、 i7 、 Ultrabook 等名詞皆是許多消費者不見得知道細節卻朗朗上口的產品與技術; Intel 在 HPC 高效能運算年度盛會 SC2022 前夕,宣布推出 Intel Max 系列產品,包括代號 Intel Xeon CPU Max 與 Intel Data Center GPU Max ,兩個產品線首世代產品分別對應等到望穿秋水的 Sapphire Rapids HBM 處理器,以及 Ponte Vecchio 加速 GPU 。 ▲ Intel Max 系列預計於 2023 年 1
2 年前