
在 GTC 2012 中, NVIDIA 執行長黃仁勳也在 Keynote 演說時,一併介紹 Kepler 的另一面,也就是針對專業平行運算的新一代 Tesla 運算處理器。所謂的運算處理器,就是一張專門為了平行運算技術的附加卡,雖然基本結構與專業繪圖卡相同,不過完全捨棄影像輸出,只為運算運用存在。
全新一代的 Tesla 運算處理器帶來哪些改變呢?跳轉繼續。
Kepler 架構的運算處理器目前公佈兩個款式,分別是已經上市的 Tesla K10 ,以及預計在 10 月份推出的 Tesla K20 ;這一代的 Tesla 運算處理器擁有三個特色,分別是 SMX 架構、 Hyper-Q 以及 Dynamic Parallelism ,後兩者更是僅有 K20 獨享的技術。
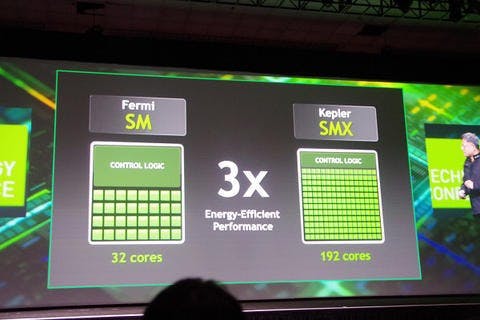
SMX 架構就是這一代 Kepler 架構的重點,相較於 Fermi 的架構, Kepler 的 CUDA 核心大幅增加,並且減少 DIE 當中的控制邏輯,將部份邏輯管理轉移到軟體層面;大幅增加的核心可以提昇運算效能,而把複雜的硬體管理邏輯部份轉移到軟體管理,可以減少核心架構中控制邏輯的發熱,相較 Fermi 的 SM 架構,全新的 SMX 架構擁有高達三倍的效能能耗比。

Hyper-Q 則是處理器資源與線程分配的技術,相較 Fermi 架構,僅能用單一 CPU 溝通 GPU 進行線程 ,使用 Kepler 架構 K20 將能讓最多 32 個處理器核心同時與 GPU 溝通並同時進行多線程,減少 GPU 的閒置並能夠提昇平行運算的速度。

Dynamic Parraleism 技術則是改善過去處理器與 GPU 之間必須反覆溝通的處理程序,過去的架構在執行 Kermal 時,處理器必須先與 GPU 溝通並回傳訊息後再由 CPU 產生下一步的 Kernal 並回傳到 GPU ,整個執行就是不斷重複這樣個溝通模式。但是這項技術 CPU 只要將訊息交給 Kepler GPU 後,就會由 GPU 端自行產生接下來的 Kermal 並告知 GPU 下的核心分配工作,最後把運算成果回傳給 CPU 。
Tesla K10 就是目前 GTX 690 的姊妹品,與 GTX 690 一樣為 320 Gbps 記憶體頻寬;然而 Tesla K20 則是代號 GK110 的新一代 GPU ,預期擁有高達 71 億個電晶體,記憶體頻寬為 384bits ,會場有媒體提問實際記憶體量,但 NVIDIA 未正式回應,僅提到會視市場需求而決定,正式上市時間為 10 月左右。
根據 NVIDIA 提供的新聞資料, K20 預期將會被運用在由美國田納西橡樹嶺國家實驗室打造的全新Titan超級電腦,以及伊利諾州立大學香檳分校的國家超級電腦應用中心打造的Blue Waters系統。



















