
AI 技術在近年為許多產業帶來顯著的升級,其中也包括半導體設計產業,諸如 Google 日前公布由 AI 協助設計的晶片論文,其中提到 AI 可跳脫人類既有的思維框架,僅考慮效率最佳化,能使晶片更具效益;而 NVIDIA 近日也公布一則由 AI 輔助設計新一代加速 GPU 產品 NVIDIA H100 晶片的部落格文章,就提到 NVIDIA H100 內部有高達 1.3 萬條 AI 設計的電路,且相較目前最先進的 EDA 工具的結果可縮減 25% 面積。

NVIDIA H100 主要仍是由當前最先進的 EDA 工具進行設計,不過導入名為 PrefixRL 的 AI 輔助工具,借助物理模擬方式進行線路設計的最佳化,並以縮減面積、降低延遲與減少功耗為三大設計宗旨;透過 PrefixRL 進行線路調整,相較傳統 EDA 工具的成果縮減高達 25% 的面積。
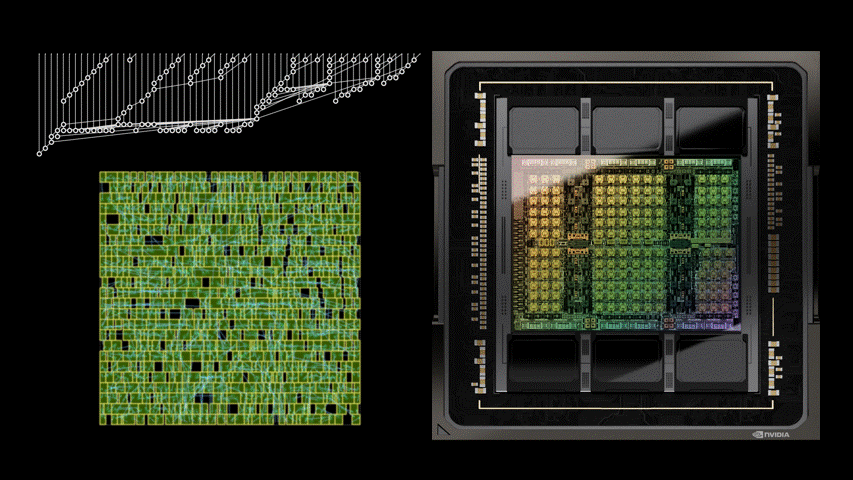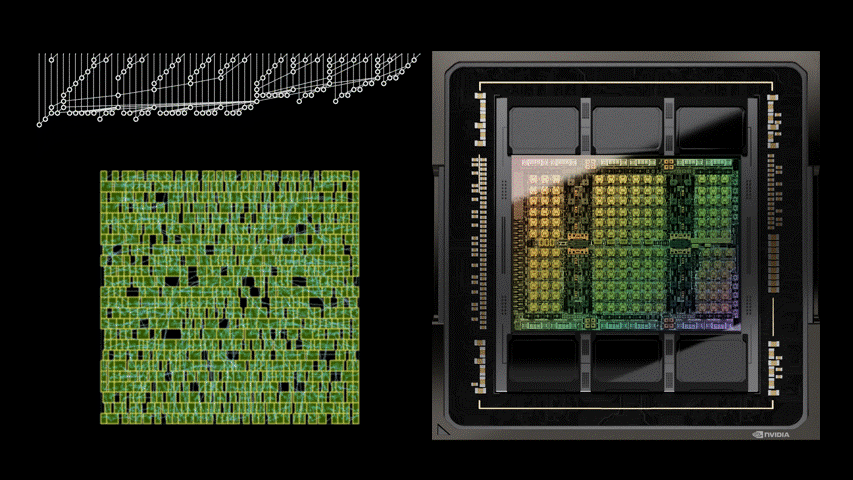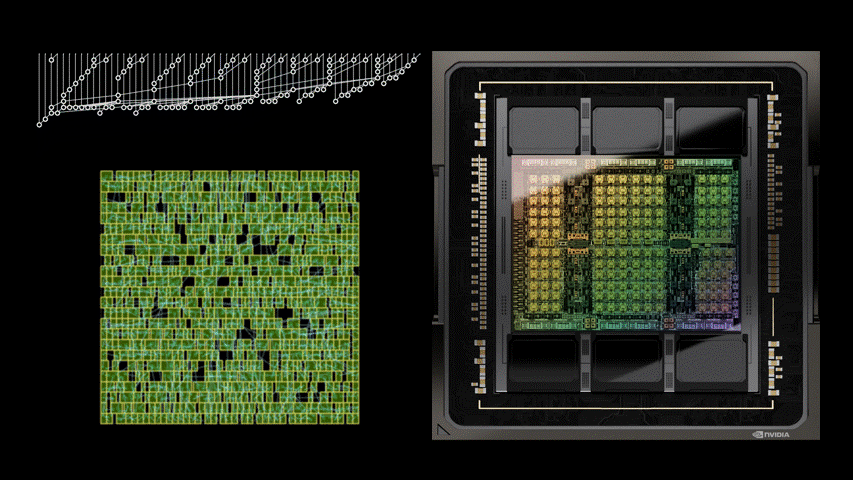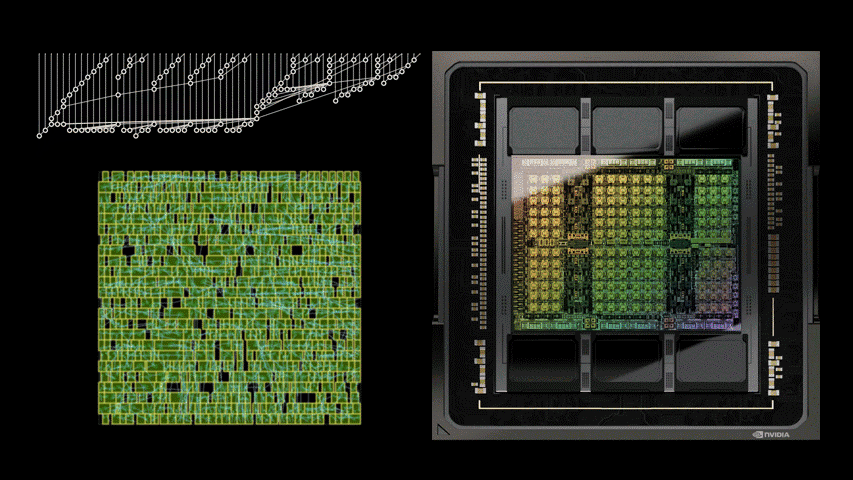
然而 PerfixRL 是一項需要重度運算效能的工具,需仰賴高度的物理模擬,若是使用傳統方式,單一個 GPU 就需要搭配高達 256 個 CPU ,並且花費 32,000 GPU 小時也僅能產生 640 億個結果,執行效率過於低落;故 NVIDIA 為了使 AI 晶片設計得以實用,是透過 NVIDIA Raptor 分散式學習技術提升效率, Raptor 可借助工作調度、自定義網路、 GPU 感知數據結構等特質,進行跨 CPU 、 GPU 與 Spot 的混合分工。



















