產業消息 nvidia gpu quantum 量子運算 NVIDIA A100 QODA NVIDIA 公布量子與經典混合運算平台 QODA ,將量子運算投入 AI 、超算、健康與金融研究 NVIDIA 宣布推出量子與經典混合運算平台 Quantum Optimized Device Architecture ( QODA ),只在打造精簡的量子與經典程式編寫模型,並提供開放、統一的環境,使研究者能更輕鬆投入量子運算開發與研究,並享受容易開發的量子與經典混合運算技術; QODA 可在科學超級運算中心與具備 GPU 加速的 NVIDIA DGX 系統、公有雲環境執行,借助 QODA 即可在 GPU 加速的超算系統使用 NVIDCIA Quantum 模擬完整量子應用程式,並使量子運算與既有經典運算之應用程式結合,希冀藉兩者的混合運算於 AI 、 HPC 、健康、金融與學術研究帶來突 Chevelle.fu 2 年前
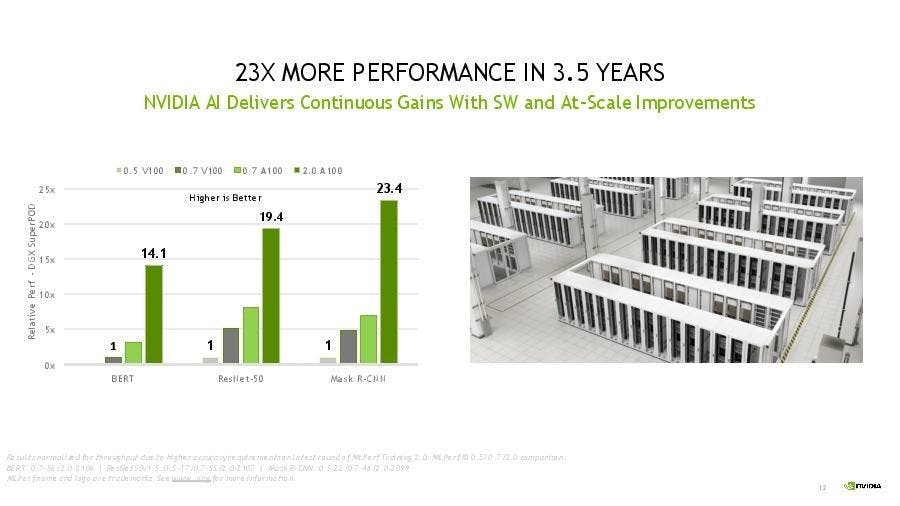
產業消息 nvidia gpu 深度學習 機器學習 NVIDIA A100 MLPerf NVIDIA 與合作夥伴公布最新 MLPerf 基準測試,不僅效能出色且仍為唯一執行所有測試項目的運算平台 NVIDIA 可說是引領異構加速 AI 技術的廠商,不過隨著 AI 加速技術廣泛被市場採納,有越來越多的競爭對手也推出 AI 加速器產品,並試圖挑戰 NVIDIA 的領先地位; NVIDIA 稍早公布第四年參與 MLPerf 基準測試成績,除了仍在各項基準測試維持出色的成績,已經上市兩年的 NVIDIA A100 GPU 仍席捲各項測試成績,在 8 項訓練測試奪下 6 項最快完成的成績,同時也是唯一一款能夠完成 MLPerf 訓練 2.0 八個完整測試項的平台,顯見 NVIDIA 加速平台不僅具備高效能,也能涵蓋各類主流 AI 訓練與加速。 ▲ NVIDIA 的 Saleen 超算 AI 系統 Chevelle.fu 2 年前
產業消息 nvidia AI 高通 加速器 NVIDIA A100 Jetson AGX Orin NVIDIA 借助軟體調整使 NVIDIA A100 在一年內 AI 性能提升 5 成,全新 Jet AGX Orin 奪下邊際推論性能之冠 雖然 NVIDIA 在 GTC 大會公布全新一代加速器 NVIDIA H100 ,性能聲稱比起目前 NVIDIA A100 有飛躍性的提升,但這不代表 NVIDIA 推出新硬體後就不再服務舊世代架構的用戶, NVIDIA 今日公布全新的 MLPerf v2.0 推論性能結果,借助在軟體不斷的革新,相較去年公布的結果,使 NVIDIA A100 的效能提升達 50% ;此外也隨著新一代嵌入式超算平台 Jetson AGX Orin 的問世, Jetson AGX Orin 借助全新硬體架構奪下邊際運算系統的效能王者頭銜。 ▲借助軟體持續精進, NVIDIA A100 相較去年表現最高提升達 50 Chevelle.fu 3 年前
產業消息 nvidia gpu AI Facebook meta NVIDIA A100 Meta 與 NVIDIA 合作打造最大 NVIDIA A100 AI 超算系統 RSC , 2022 年底將擴充到 16,000 個 GPU Facebook 母公司 Meta 宣布繼 2017 年後再度採用 NVIDIA GPU 技術打造第二世代 AI 研究基礎設施 RSC ( Research SuperCluster ),目前已經完成第一階段的架設,採用 760 套 NVIDIA DGX A100 節點、共 6,080 個 A100 GPU ,並預計在 2022 年末第二階段完工後一舉擴充到 16,000 個 GPU ,推估性能達 5 exaflops 混合精度 AI 性能,規模勝於微軟 AI 研究室的 10,000 個 GPU ,屆時 RSC 將成為地表最大型的 A100 系統。 RSC 的目的是作為 Meta 新一代 AI Chevelle.fu 3 年前
產業消息 gpu nvidia turing NVIDIA A100 NVIDIA Ampere RTX 3080 Ti RTX 3070 Ti NVIDIA 在企業級產品與甫發表的筆電版 RTX 3080 Ti 、 RTX 3070 Ti 解放晶片架構中的隱藏區塊,可將部份工作流自 CPU 轉移到 GPU 根據 Tom's Hardware 報導, NVIDIA 自 Turing 架構到新一代的 Ampere 架構一直有個未被啟用的區塊,稱為 GSP ( GPU System Processor ),不過近期 NVIDIA 悄悄為專業級處理器以及今年在 CES 所公布的筆電版 RTX 3070 Ti 與 RTX 3080 Ti 開啟這個至今還未開啟過的小小區塊,別看 GSP 僅占核心一小部分,未來將可能會進一步善用 GPU 的性能。 GSP 是一項協同控制器架構,主要的功能是負責把部分原本由 CPU 執行的任務轉移到 GPU 上,簡單的說就是以理想而言可以把系統認定以 GPU 較適合的工 Chevelle.fu 3 年前
產業消息 nvidia 邊際運算 NVIDIA A100 NVIDIA Ampere DGX A100 即便面對競爭對手前仆後繼, Forrester 報告仍認定 NVIDIA GPU 為當前人工智慧基礎建設代名詞 AI 人工智慧雖不是新技術名詞,不過近年隨著硬體設計、異構運算、演算法等技術精進,終於開花結果並廣泛被應用在各領域,也使得 AI 技術進入群雄割據的狀態,除了引領 AI 發展成長茁壯的 GPU 以外,包括獨立加速器、 FPGA 或是整合在各晶片中的推論架構也如雨後春筍,甚至幾家大型資料中心也紛紛投入自定義架構打造針對特定領域的 AI 晶片;可視為這波 AI 浪潮先驅的 NVIDIA 在面對當今的局勢,仍在 Forrester Wave AI Infrastucture Q4 2021 的報告中,被指出 NVIDIA 的 DNA 存在於所評估的每一個 AI 基礎設施中,幾乎可視為當前 AI 基礎 Chevelle.fu 3 年前
產業消息 nvidia AI 智慧醫療 NVIDIA A100 NVIDIA攜手研華、廣達、三總、花蓮慈濟等,在台灣醫療科技展展現台灣智慧醫療實力 醫療影像應用是 NVIDIA 的 AI 技術相當被看重的重要發展領域, NVIDIA 甫在美國 RSNA 展現 NVIDIA AI Enterprise 的癌症應用成果以及公布針對聯合學習的開源軟體 NVIDIA FLARE ,亦在近日的 2021 台灣醫療科技展與研華、廣達兩大系統商,以及三軍總醫院、花蓮慈濟醫院等共同展現彼此在智慧醫療的成果。 三軍總醫院在 2020 年 6 月與 NVIDIA 簽署合作備忘錄加入 COVID-19 聯合學習計畫,同時合作成果亦在今年 9 樂於 Nature Medicine 期刊發表;此次 NVIDIA 與三軍總醫院在展會中展示與國際醫療機構打造資料庫、調 Chevelle.fu 3 年前
產業消息 nvidia gpu AI NVIDIA A100 NVIDIA FLARE NVIDIA 公布 AI 與圖形加速在醫療領域新進展,以開源套件 FLARE 提供聯合學習、借助 AI Enterprise 鎖定癌症目標 NVIDIA 今日藉著北美放射學會年會 RSNA 宣布兩項結合旗下圖形與 AI 技術的醫療應用進展,其一是宣布針對聯合學習的全新開源軟體 NVIDIA FLARE ,另一則是荷蘭癌症研究所、醫療保健公司 Vyasa 與 iCAD 借助 NVIDIA AI Enterprise 軟體套件提供結合 AI 的醫療影像的應用。 NVIDIA FLARE 將協作式人工智慧引領至醫療領域 NVIDIA FLARE 是針對醫療領域提供協作式人工智慧的軟體開發套件,旨在透過分散式的聯合學習技術,使著重隱私或資料稀少、機密與缺乏多樣性的特殊醫療影像能夠透過轉化為分散式架構並進行機器學習與深度學習,當前已經應用在 Chevelle.fu 3 年前
產業消息 ARM nvidia gpu x86 NVIDIA A100 NVIDIA Grace Ampere Altra NVIDIA 首度公開搭配 NVIDIA A100 搭配 Arm 架構伺服器效能,展現不遜於搭配 x86 處理器的出色表現 NVIDIA 首度公開 NVIDIA A100 搭配 Arm 架構 CPU 的效能表現,在最新 MLPerf 的基準測試結果證實無論是搭配 x86 或是 Arm 架構皆有出色的水準,證實 Arm 架構伺服器不僅有出色的能源效率,在搭配 NVIDIA A100 GPU 的異構運算同樣有出色的性能,這也是 MLPerf 資料中心類別首度於 Arm 架構系統進行測試,同時 NVIDIA 也連續三度在 MLCommons 推論測試基準創下效能與能源效率紀錄, NVIDIA 亦為唯一一家自第一輪起至今不間段公布 MLPerf 成績的公司。 ▲ NVIDIA 證實在相近配置之下, Arm 架構表現並不遜於 Chevelle.fu 3 年前
產業消息 gpu AI 超級電腦 polaris Aurora AMD EPYC NVIDIA A100 Ponte Vecchio NVIDIA 與 HPE 協助阿貢國家實驗室設置 1.4 PETAFLOPS AI 算力的 Polaris 超級電腦,填補採全 Intel 技術 Aurora 系統延後上線的空窗 根據原本 Intel 與隸屬美國能源局的阿貢國家實驗室簽署的合約, 2021 年將啟用結合 Intel Xeon CPU 、 Xe GPU 與 Optane DC 儲存的 Exaflops 等級超級電腦 Aurora ,不過隨著 Ponte Vecchio 的正式推出時間延至 2022 年, Aurora 的上線時間也被迫順延;不過阿貢國家實驗室為了填補 Aurora 上線的空窗期,先導入基於 NVIDIA A100 Tensor GPU 的超算系統 Polaris ,以 AMD EPYC CPU 結合 NVIDIA A100 GPU 提供與 44 PetaFLOPS 的峰值雙精度算力,作為屆 Chevelle.fu 3 年前