
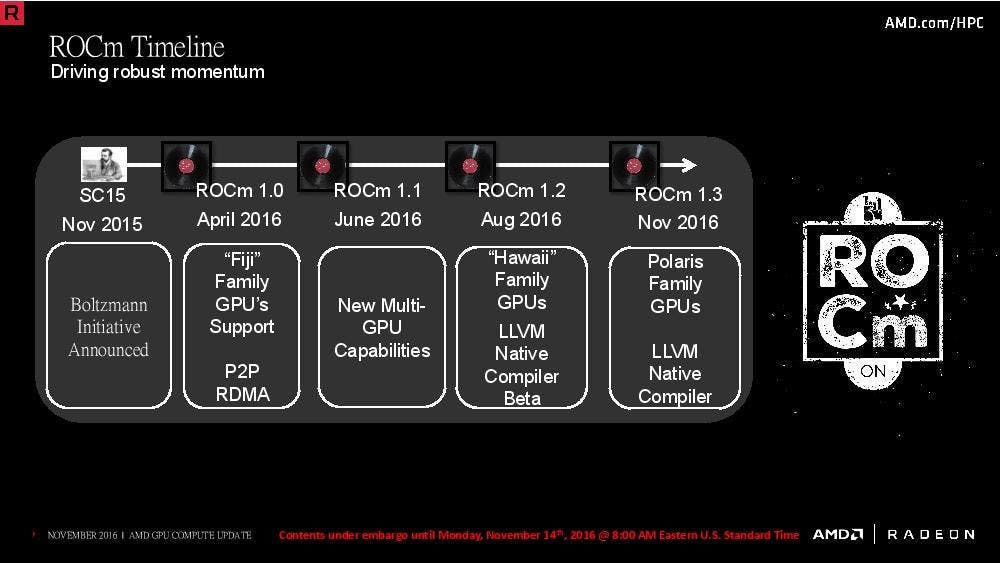
AMD Open Compute 計畫 ROCm 邁入 1.3 版,開始支援 Polaris 架構
AMD 在 2015 年的 SC15 大會開始提出 Open Computing 的計畫,希望藉由開源的方式推廣 GPU 加速的異質運算,同時賦予此計畫 ROCm ( Radeon Open Compute Platform )的名稱,歷經一年左右的時間也在 SC16 大會公布了最新的 ROCm 1.3 ,主要也加入最新的 Polaris 架構 GPU 的支援。 ROCm 計畫的宗旨仍舊是希望藉由開放平台的方式藉此推廣 Radeon GPU 於異質運算的應用,故除了 AMD 的 Fiji 、 Hawaii 以及 Polaris 架構 GPU 以外,可與包括 AMD 、 Intel 等 x86
8 年前


















