

# gpu 全攻略
- nvidia
- intel
- AI
- RTX 3080
- NVIDIA Ampere
- 光線追蹤
- ray tracing
- Intel Xe
- Radeon RX 6800XT
- Xe-HPG DG2
- ASUS
- rog strix
- epic games
- Hopper
- CPU
- ARM
- hpc
- gpgpu
- 工作站
- A64FX
- Apple Silicon
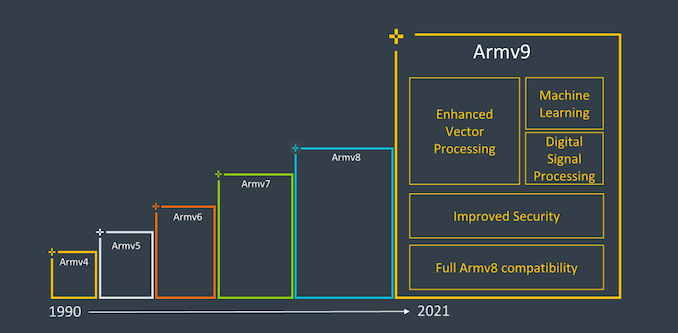
- Armv9
- 硬科技
- 簡報王
- RTX 3080 Ti
- RTX 3070 Ti
- 比特幣
- 挖礦
- 數位貨幣
- 乙太幣
- NVIDIA A100
- CMP HX
- nvidia gtc
- Ampere
- GTC 21
- vmware
- 人工智慧運算
- vSphere
- AMD
- 顯示卡
- 供貨不足








友站推薦


















