NVIDIA 於 SC18 主題演講呈現其超級運算願景,以 Tesla T4 加速器為大規模運算系統挹注效能
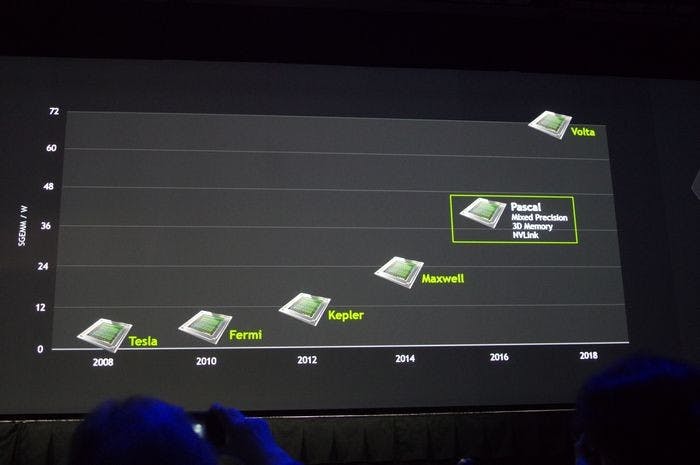
在今年超級電腦年度盛事 SC18 所公布的最新全球超級電腦榜單上,基於 NVIDIA GPU 加速的系統大放異彩,包括台灣杉 2 等多套新超級電腦系統在象徵性能的 Top500 與能耗效能的 Green 500 雙雙入榜,取得相當亮眼的表現,也驗證 NVIDIA 執行長表示透過 GPU 加速將持續推動產業摩爾定律的說法;而在 SC18 正式開始前一天, NVIDIA 執行長黃仁勳也進行主題演講,聚焦在 NVIDIA 如何透過軟硬體結合推動新一代超級電腦創新。 黃仁勳表示, NVIDIA 在 10 年前的 SC08 大會首度宣布基於 Tesla GPU 加速的個人超級電腦,而十年後的今日,基於
6 年前